Audit Feed
Public record of every signal/noise audit shipped by Verg. Each card links to the full detail page with the hypercard, probe measurements, and lifecycle events.
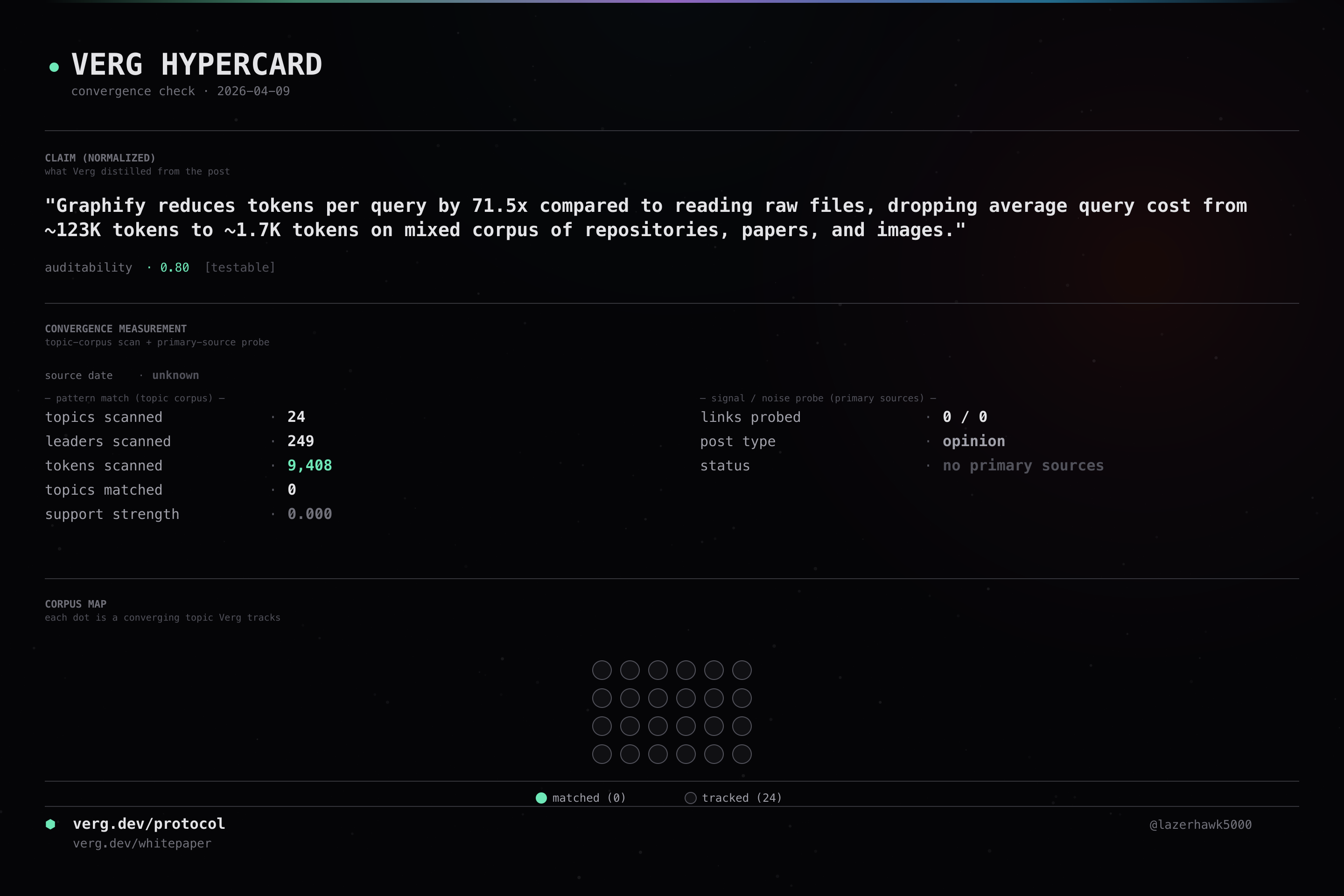
Graphify reduces tokens per query by 71.5x compared to reading raw files, dropping average query cost from ~123K tokens to ~1.7K tokens on mixed corpus of repositories, papers, and images.
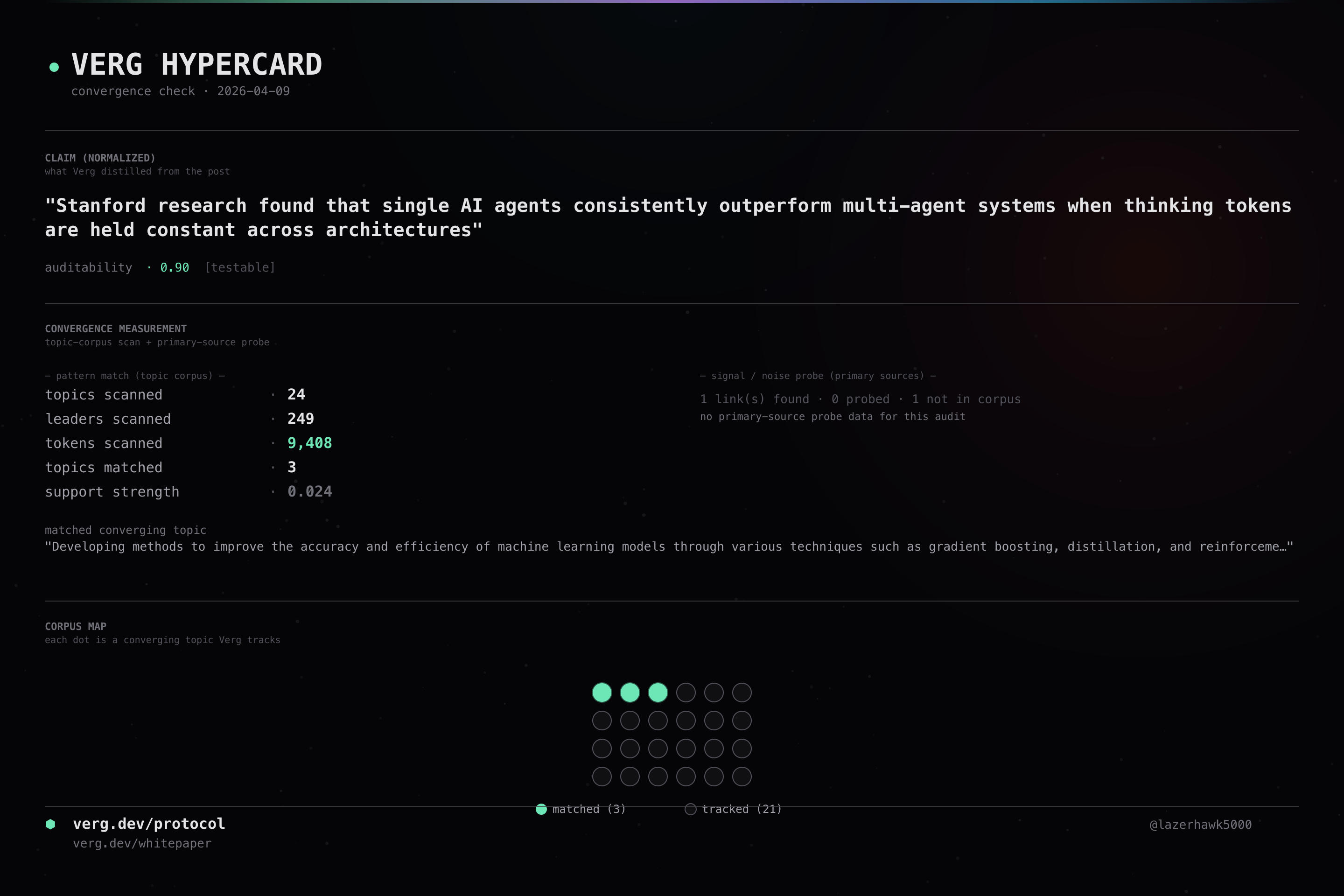
Stanford research found that single AI agents consistently outperform multi-agent systems when thinking tokens are held constant across architectures
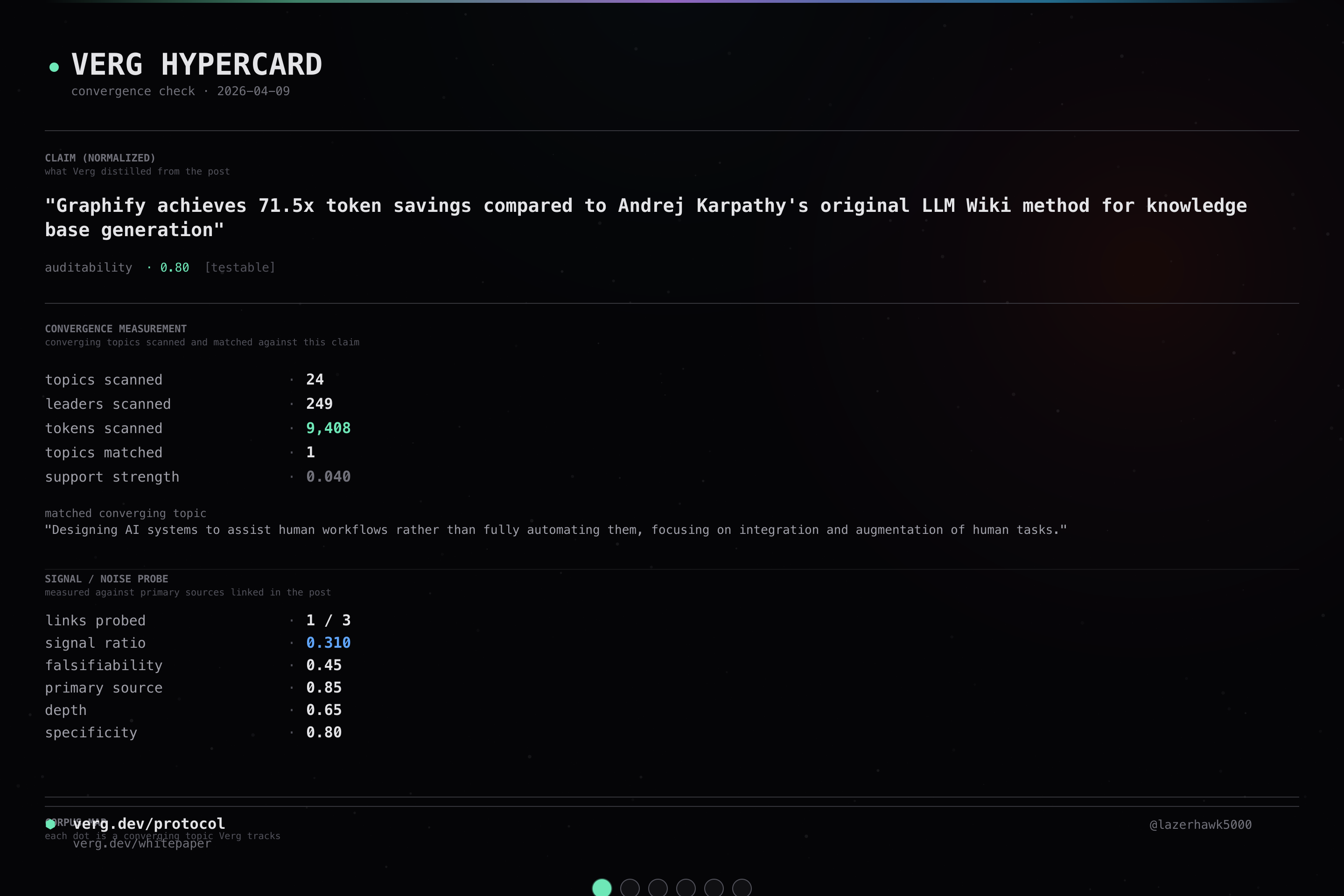
Graphify achieves 71.5x token savings compared to Andrej Karpathy's original LLM Wiki method for knowledge base generation
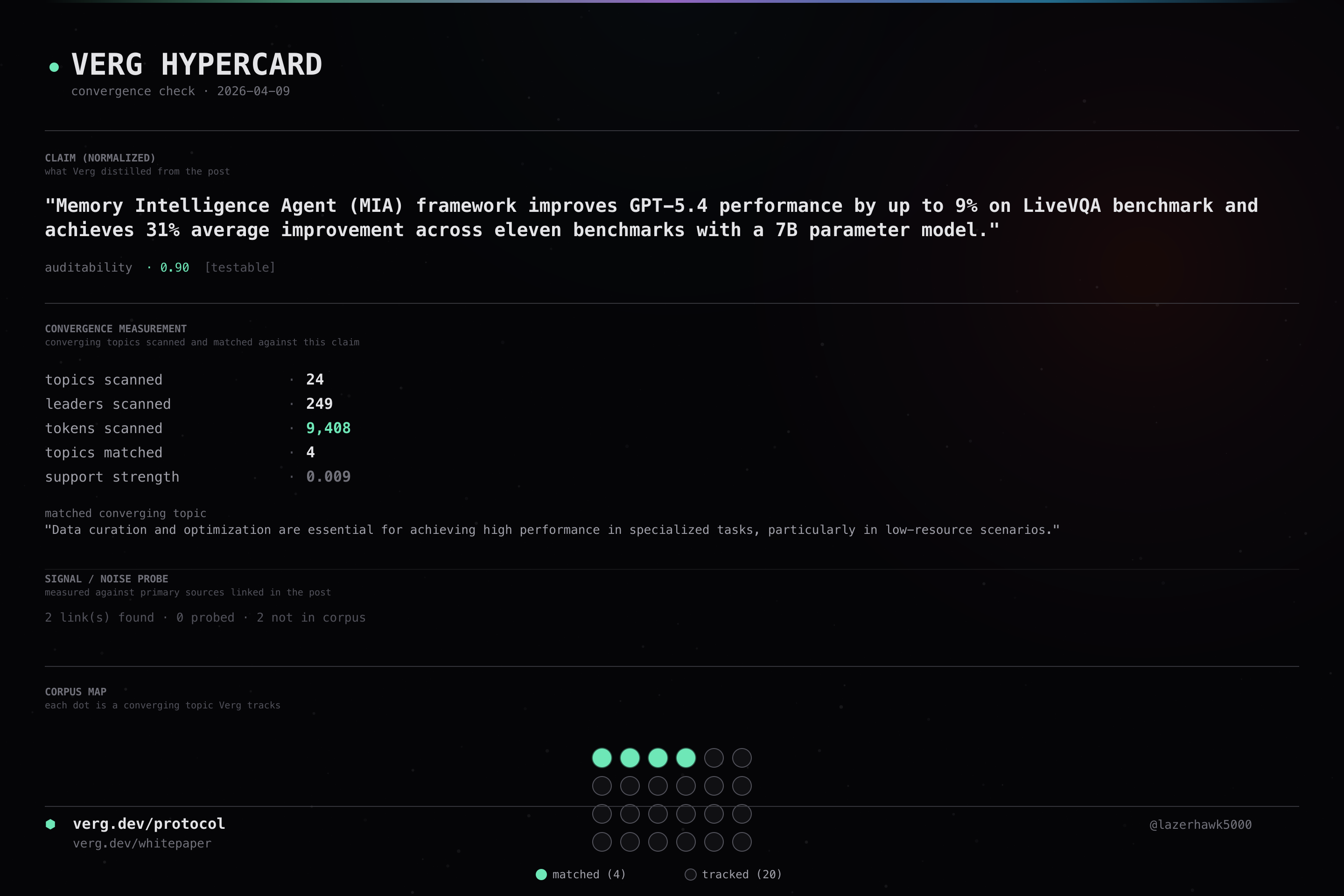
Memory Intelligence Agent (MIA) framework improves GPT-5.4 performance by up to 9% on LiveVQA benchmark and achieves 31% average improvement across eleven benchmarks with a 7B parameter model.
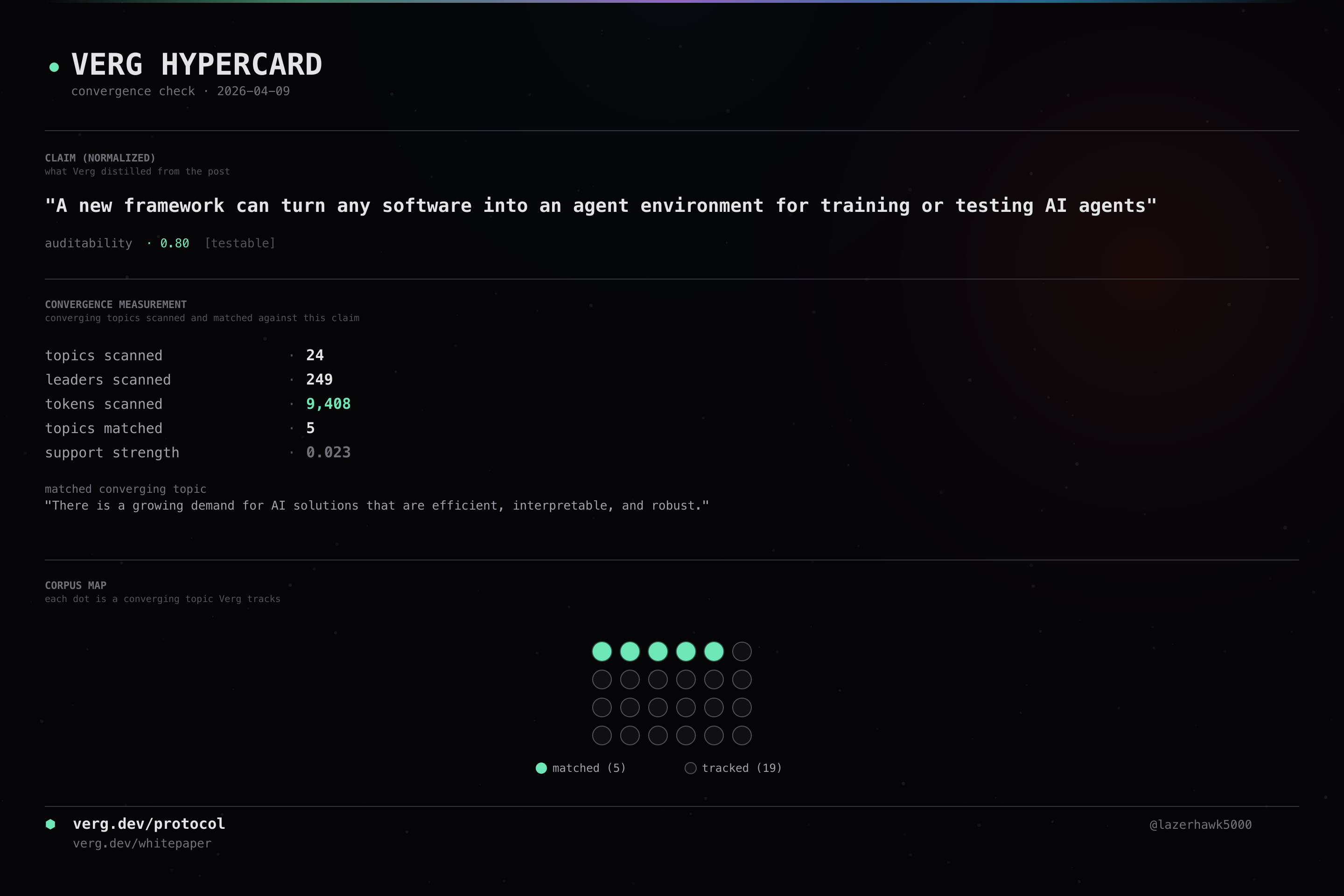
A new framework can turn any software into an agent environment for training or testing AI agents
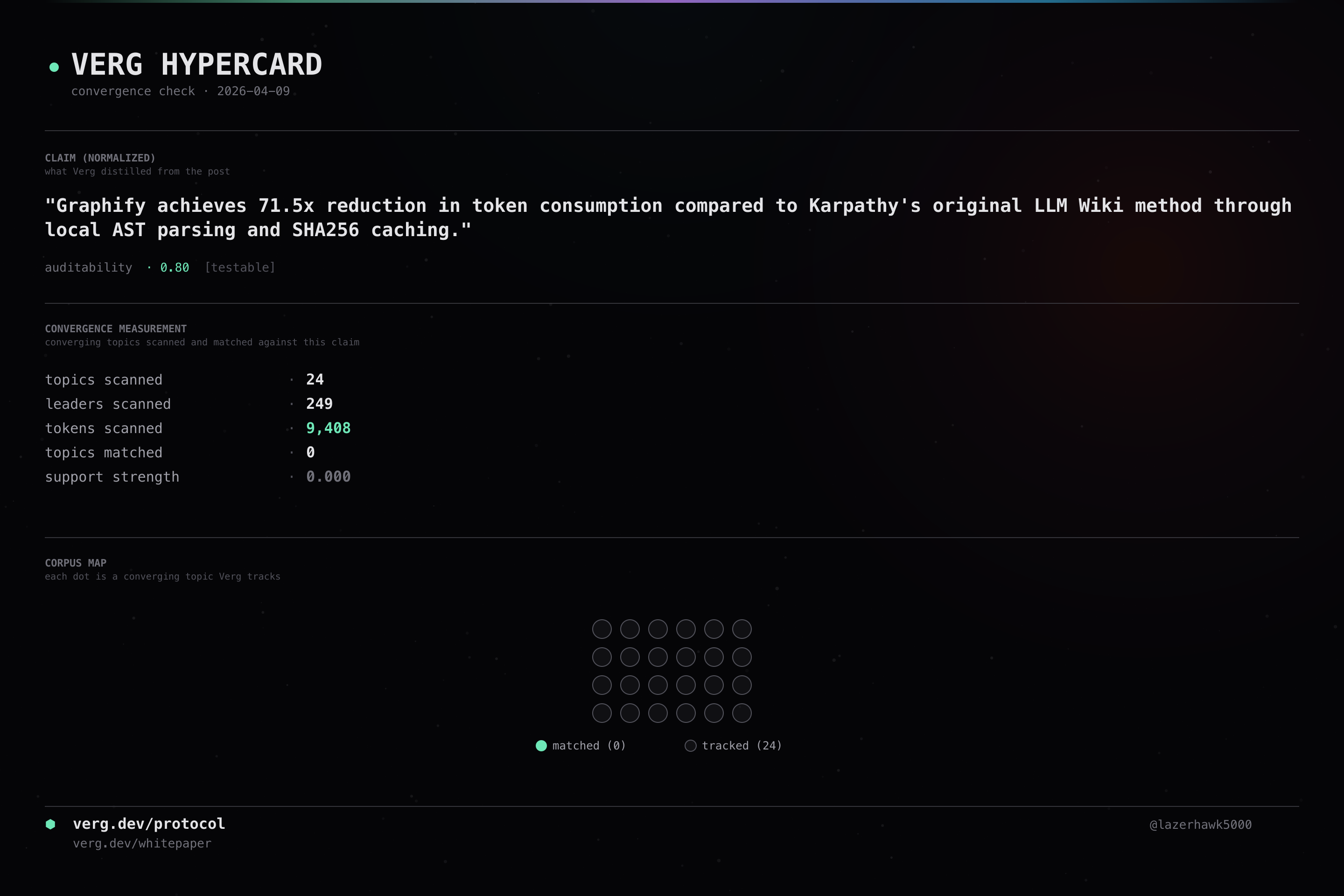
Graphify achieves 71.5x reduction in token consumption compared to Karpathy's original LLM Wiki method through local AST parsing and SHA256 caching.
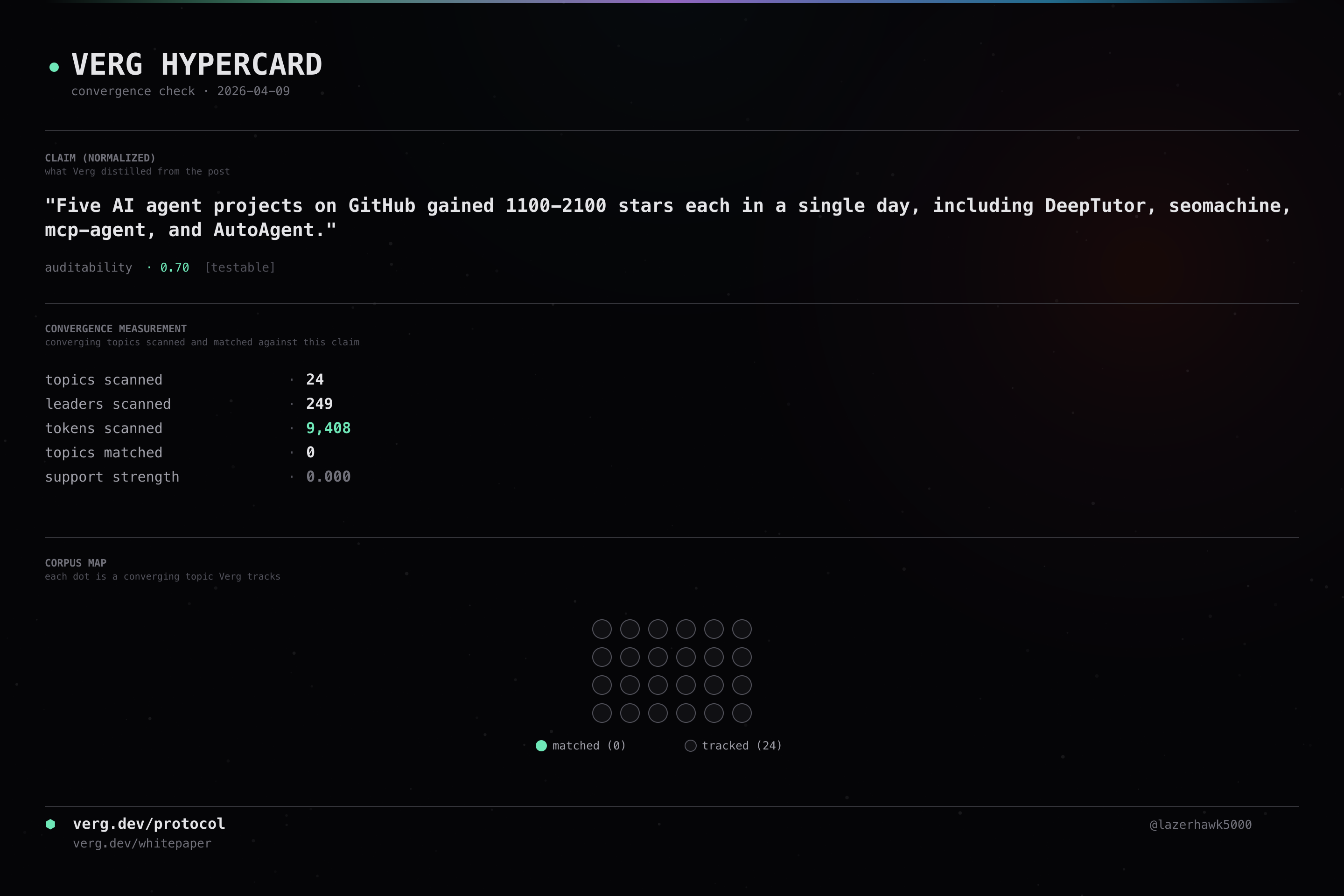
Five AI agent projects on GitHub gained 1100-2100 stars each in a single day, including DeepTutor, seomachine, mcp-agent, and AutoAgent.
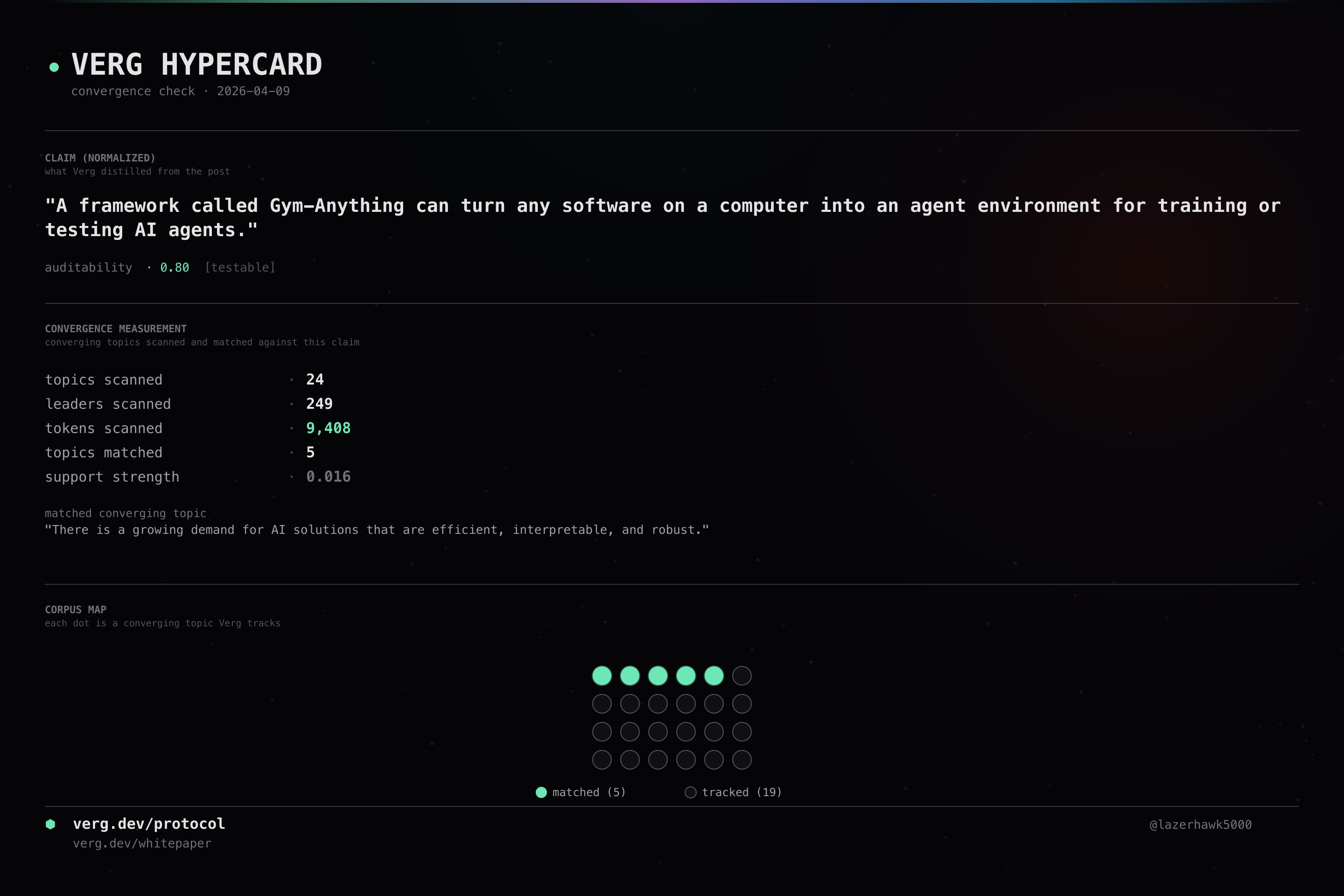
A framework called Gym-Anything can turn any software on a computer into an agent environment for training or testing AI agents.
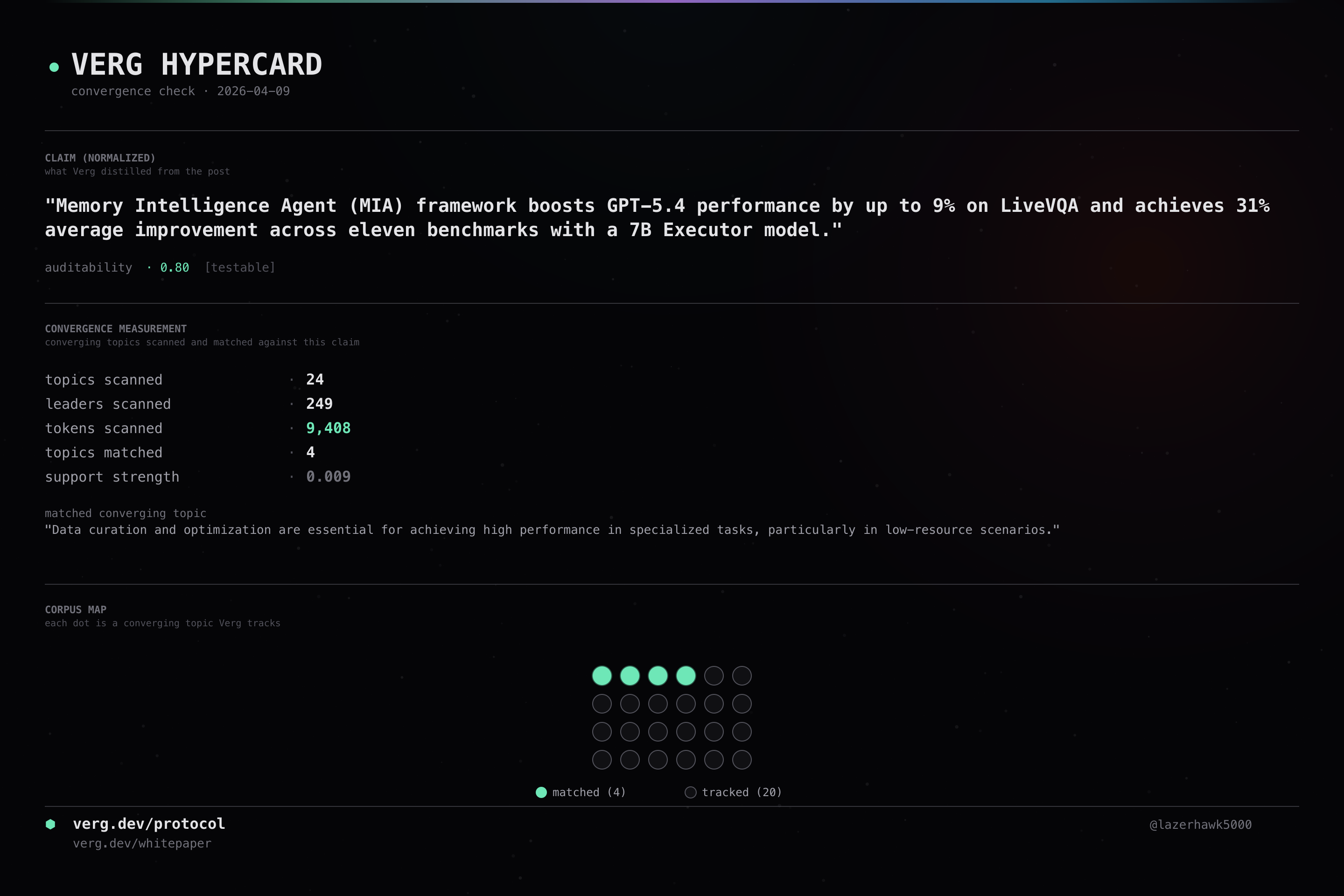
Memory Intelligence Agent (MIA) framework boosts GPT-5.4 performance by up to 9% on LiveVQA and achieves 31% average improvement across eleven benchmarks with a 7B Executor model.
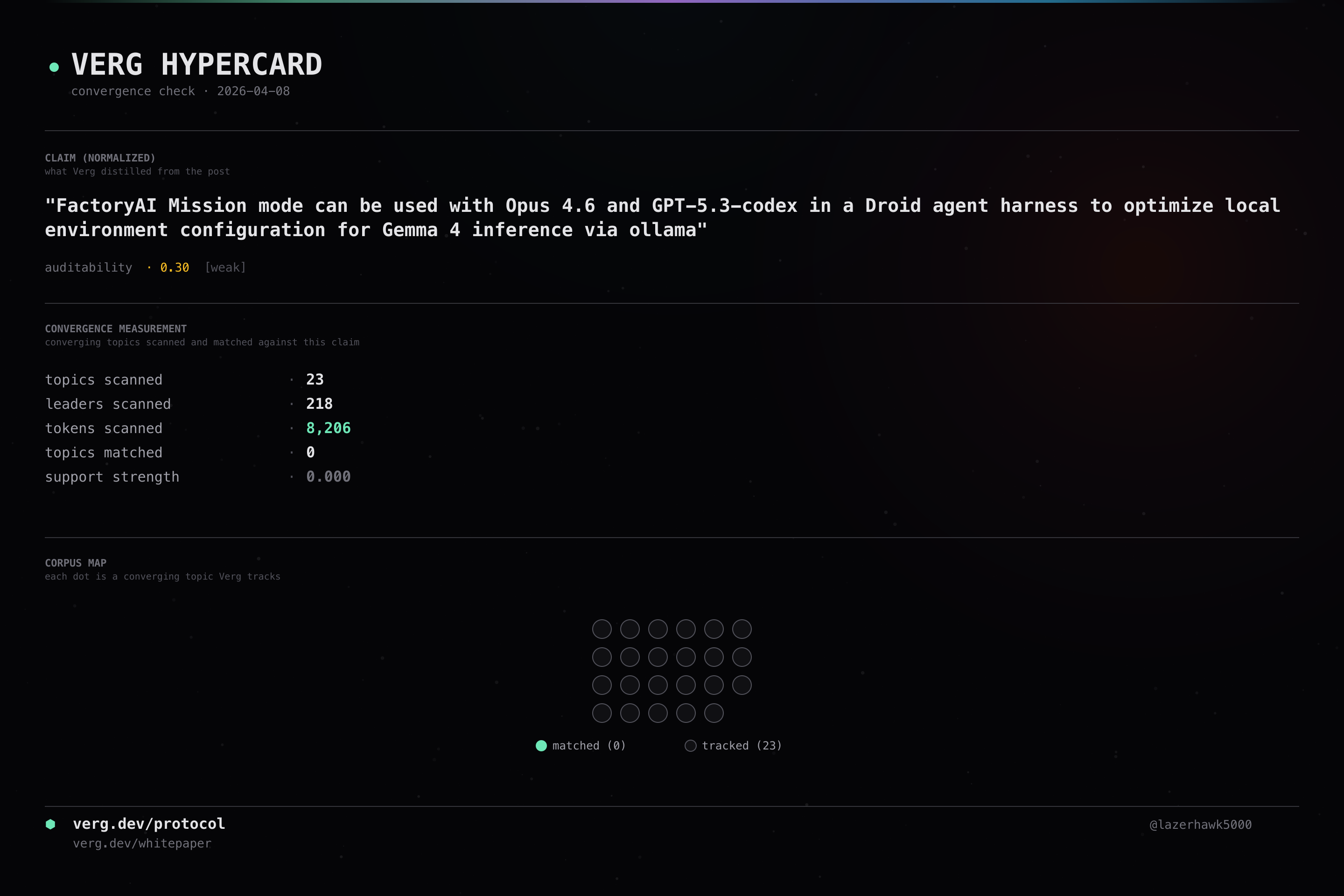
FactoryAI Mission mode can be used with Opus 4.6 and GPT-5.3-codex in a Droid agent harness to optimize local environment configuration for Gemma 4 inference via ollama
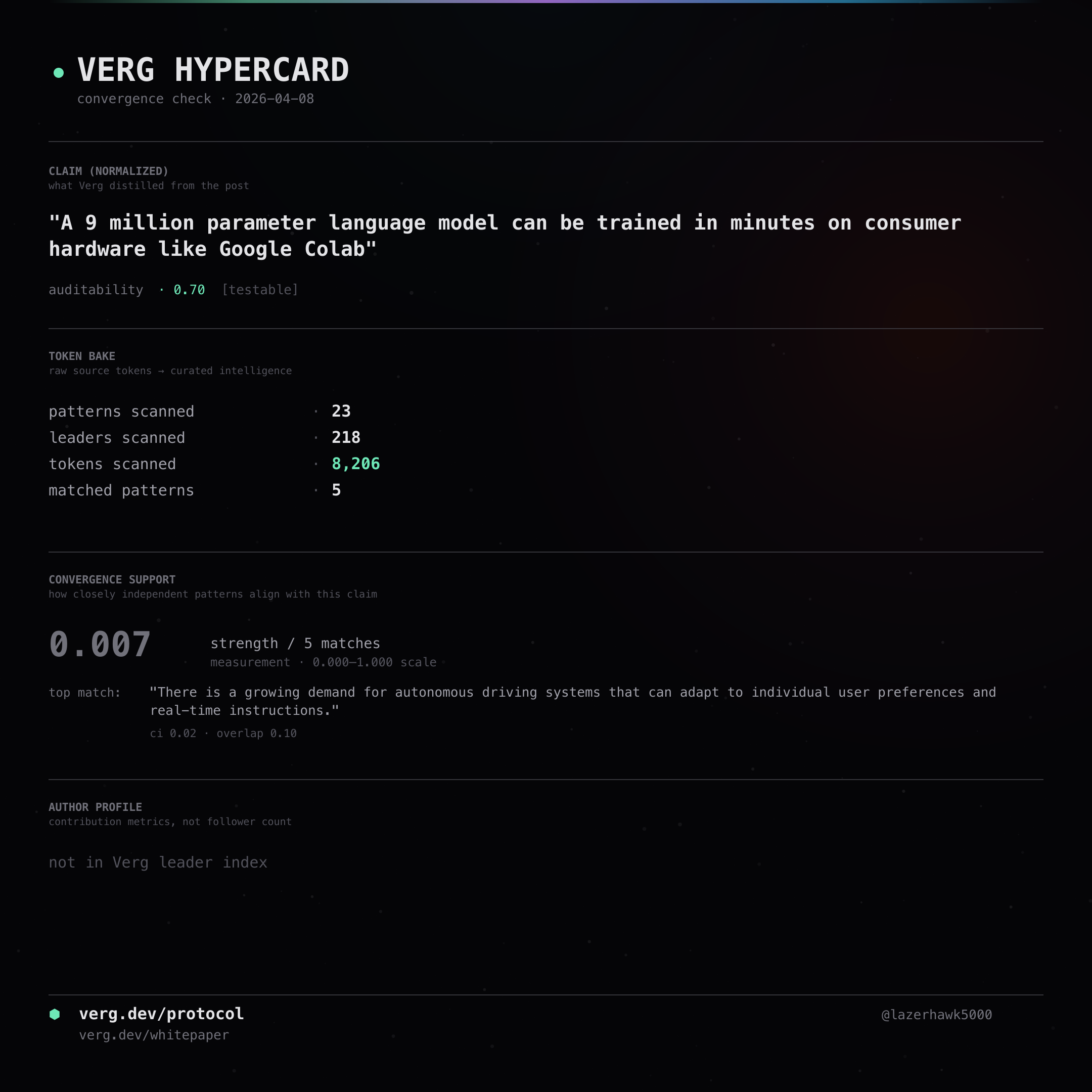
A 9 million parameter language model can be trained in minutes on consumer hardware like Google Colab
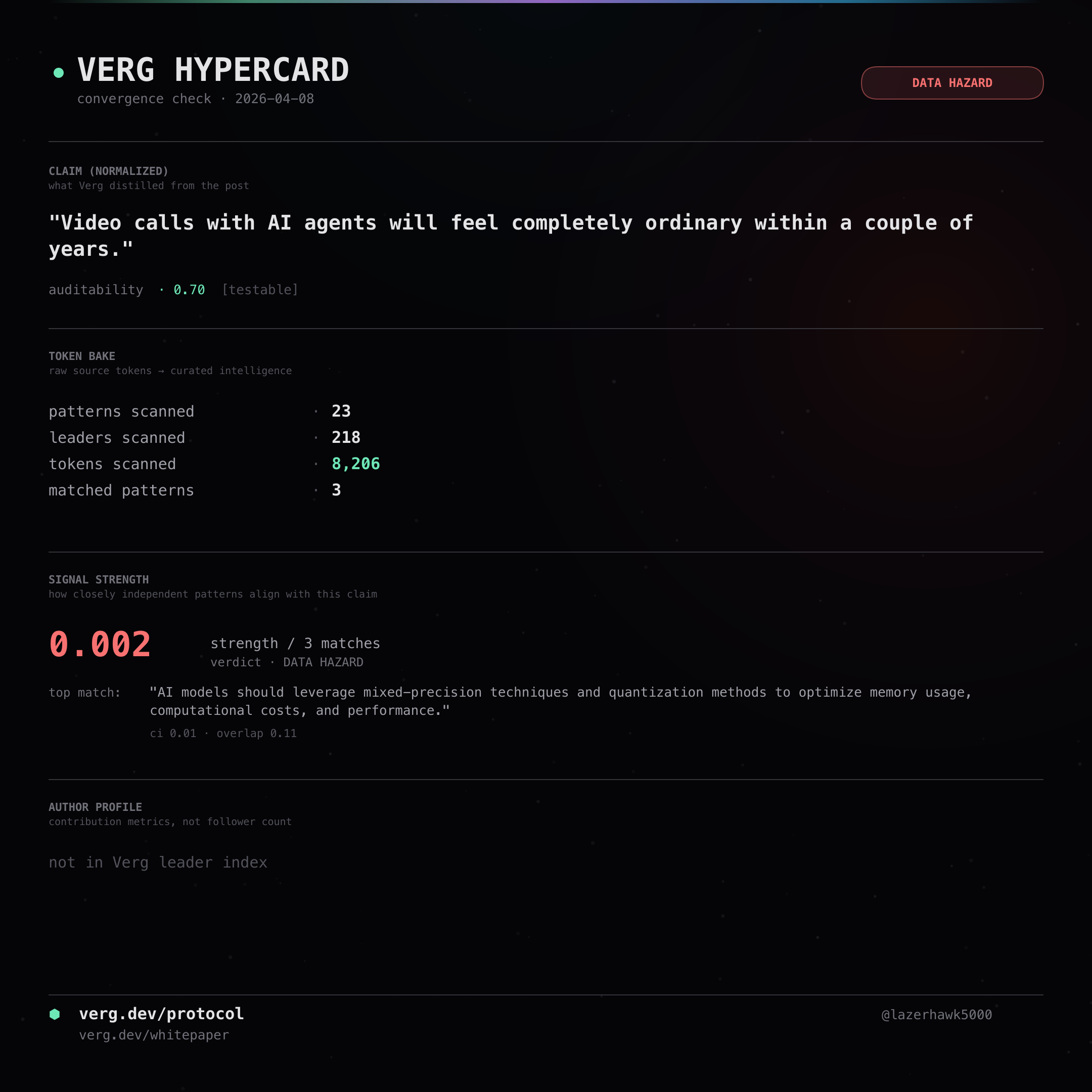
Video calls with AI agents will feel completely ordinary within a couple of years.
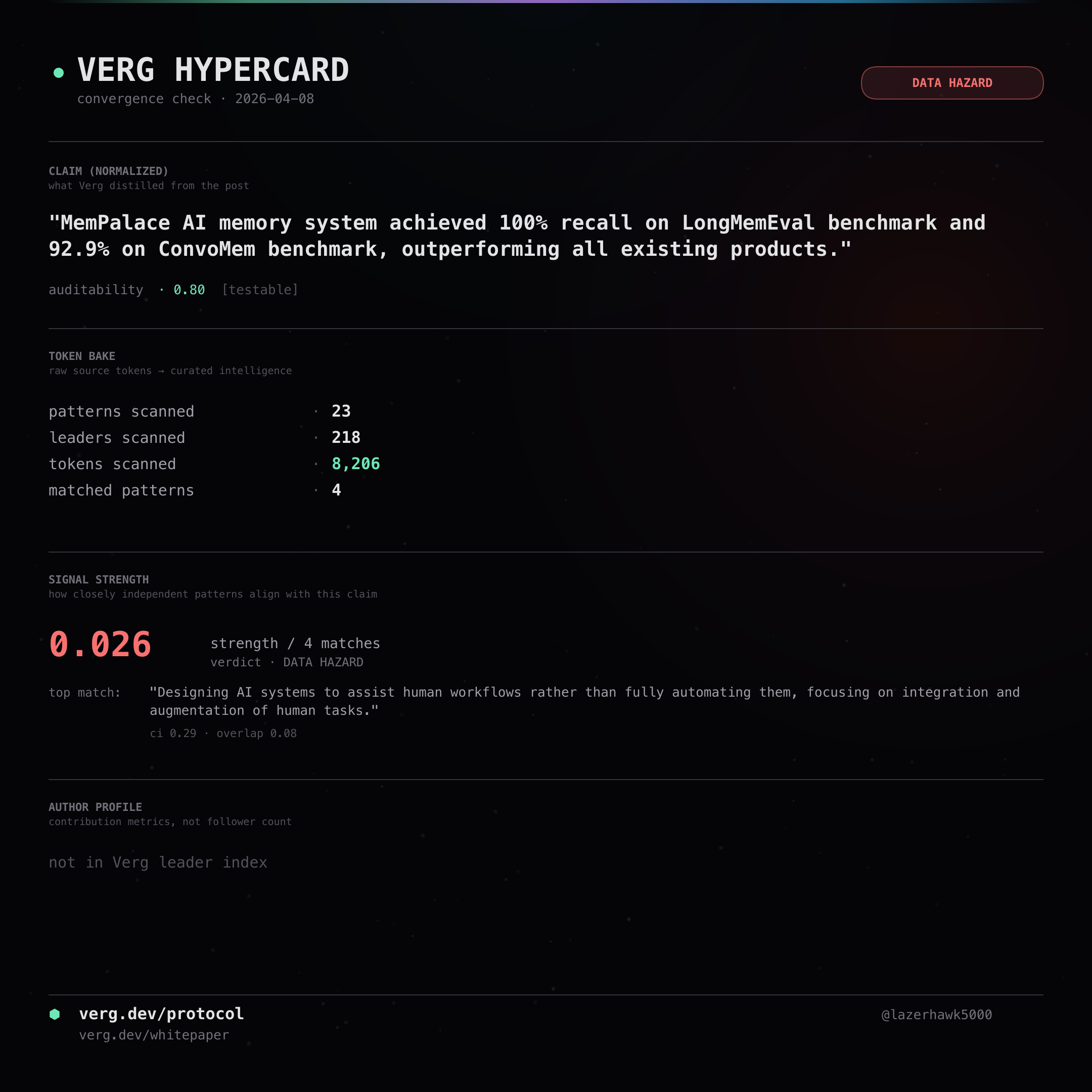
MemPalace AI memory system achieved 100% recall on LongMemEval benchmark and 92.9% on ConvoMem benchmark, outperforming all existing products.
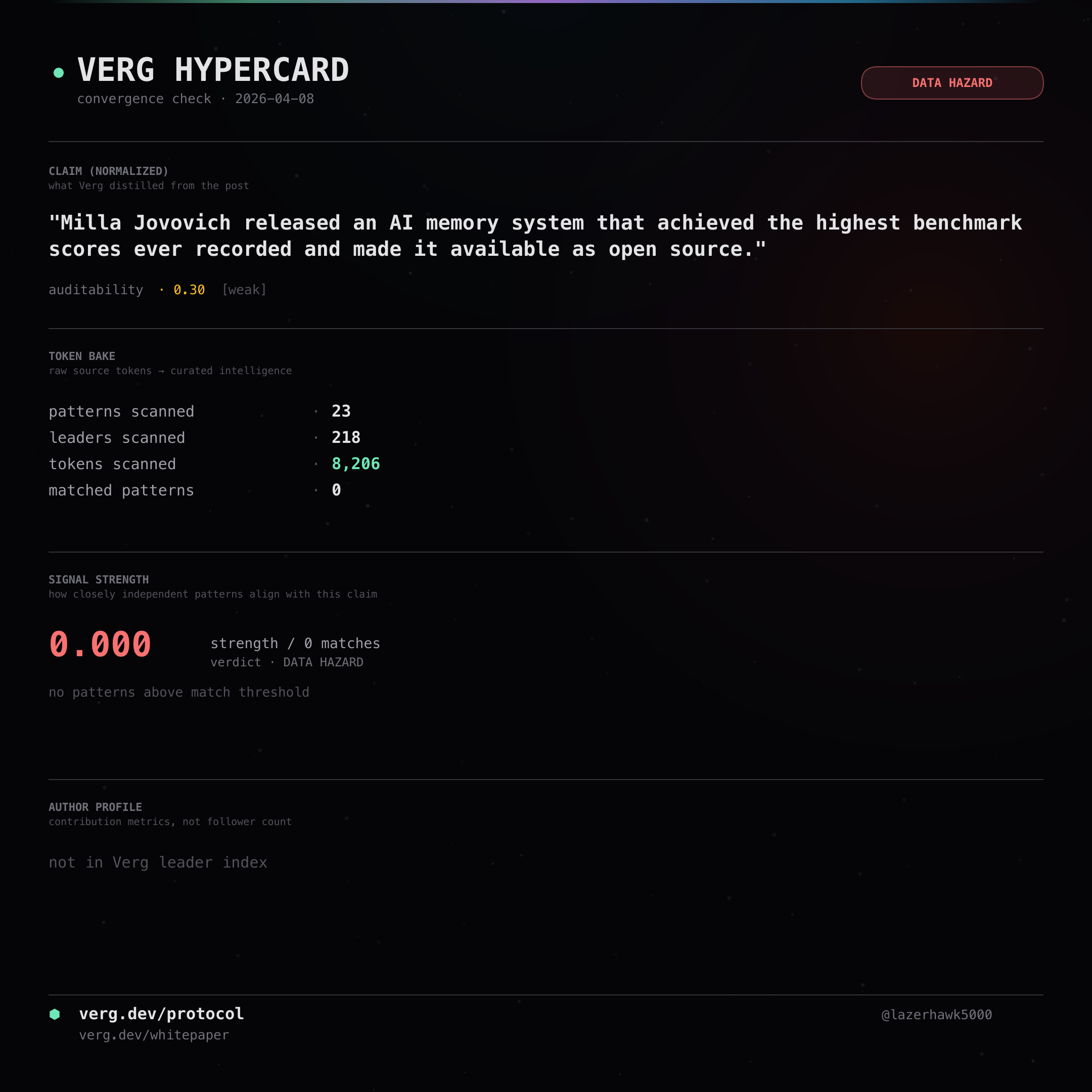
Milla Jovovich released an AI memory system that achieved the highest benchmark scores ever recorded and made it available as open source.
14 auditsshipped. Each audit measures signal/noise against Verg's open rubric — see the protocol.