The Verg Protocol
Convergence intelligence,
explained in motion.
“Verg is an attempt to meet mind to mind with the parts of the paradigm.”
Everything in one place: how the protocol works, the full whitepaper, audit feed, and self-audit measurements. Use the sticky nav above to jump between sections, or scroll through. Switch the depth toggle between simple (plain language) and nuanced (technical detail) at any time.
01 \u2014 Why
Why do we need convergence intelligence?
Three things broke at once.
The volume of indexable text published daily — papers, repos, posts, transcripts — has decoupled from any individual's reading capacity. Filtering by keyword or recency surfaces the most-amplified content, not the highest-signal content.
Recommendation engines optimize for retention and click-through. The top of any feed is selected by signals that correlate with virality, not with epistemic quality. The selection process is opaque, the optimization target is engagement, and the result is that 'what's trending' has structurally weak correlation with 'what's true' or 'what matters.'
Paradigm shifts are, by definition, low-amplitude before they happen. Any system that prunes low-engagement content prunes the early origin signals of the next consensus. This is a structural blindness: 'noise' and 'frontier' look identical to a recommender that optimizes for what's already converged.
02 \u2014 Thesis
What is convergence as signal?
Cross-community convergence, not virality.
Verg detects convergence patterns: clusters of assertions from unaffiliated sources in different communities that share the same underlying thesis. The signal isn't volume — it's cross-community reinforcement. Two people in the same community agreeing means little. Two people in different research disciplines, on different platforms, with no citation links between them, arriving at the same conclusion is a stronger signal — though unaffiliated does not guarantee fully independent. Shared platforms, benchmark releases, and news cycles can produce convergence that looks independent to surface metrics.
Manufactured virality requires coordinated amplification within or across communities. Manufactured convergence would require coordinating researchers, builders, and writers across disconnected communities to all publish similar conclusions in similar timeframes — the cost rises faster than any plausible return on the manipulation.
Echo — same room
Same community, mutual citations, growing volume. High virality. Low information value.
Convergence — different rooms
Different communities, no shared citations, same conclusion. The dotted line is the signal.
03 \u2014 How
How does the pipeline work?
Six stages. Every step measurable.
Every stage is measurable. Run logs persist as data/ledger/run_history.jsonl.
Ingest
Read from 485+ tracked sources via RSS, the GitHub API, arXiv, Semantic Scholar, podcast feeds with audio transcription, and direct site scraping. The source list is human-curated; the protocol explicitly does not crawl the open web.
Distill
Each ingested item is distilled to a small set of trend vectors — atomic claims with provenance. Distillation runs locally on Ollama (qwen2.5:14b) with structured output enforcement. Items that fail the quality gate are classified as noise rather than dropped.
Cluster
Trend vectors are merged via semantic similarity into stable cluster representations. Duplicate claims across sources collapse into one canonical vector while preserving every contributor link.
Detect
Convergence patterns emerge when contributors across different communities align on the same vector cluster without direct citation links. CI score is computed from semantic alignment, contributor count, cross-community presence, and stability over time.
Verify
PageRank ranks contributor authority; Louvain community detection groups contributors into clusters. Contributors in different communities arriving at the same conclusion produce a high independence score. Contributors in the same community produce a low one.
Classify
Patterns get classified as Signal (high CI + high independence), Frontier (low CI but unique frame, watch list), Noise (low CI + low independence — explicit echo), or Archived (was signal, dissolved). Predictions are generated against future state and graded later. Nothing is pruned — frontier classification preserves the slow-burning paradigm shifts.
04 \u2014 Measurement
What does convergence detection cost?
What 287K \u2192 12K actually means.
Token bake = sum of body_text characters from every contributing source / 4 ≈ raw input tokens. The curated artifact = JSON.stringify of every active pattern (excluding foreign-key indices) / 4 ≈ output tokens. Both are measured every run from disk; nothing is estimated. As of the most recent run: ~287K raw → ~12K curated → ~96% compression. Reproducible from data/research/token_efficiency.jsonl.
Each curated pattern contains: a tier-1 prose summary (the human-readable skim), tier-2 temporal/independence/frame analysis, tier-3 modal distribution and presupposition conflict detection, and tier-4 per-source profiles for every contributing creator. An agent ingests the full structured artifact; a human skims the tier-1 summary. The 'small summary' interpretation is one tier — the full artifact is the curated intelligence.
888K
raw tokens
source body text
64K
curated
structured artifact
12K
prose tier
human skim
92.8%
compression
measured, not estimated
Top live pattern
CI 0.140
05 \u2014 Differentiator
How is independence verified?
The dotted line is the signal.
Corroborative overlap — the foundation of intelligence analysis — says: never trust a single source. Instead, look for the overlap where sources with conflicting goals agree. Because they have no incentive to collude, their agreement is structurally harder to fake than any individual report. Verg applies this principle to information curation: convergence patterns form only where independent sources align without coordination.
Independence verification distinguishes genuine convergence from coordinated echo. PageRank computes contributor authority weight from the citation/mention graph. Louvain community detection partitions the contributor graph into modular clusters. Two contributors in the same Louvain community are likely sharing context. Two contributors in different communities arriving at the same vector cluster, with low betweenness between them, are independent — that's the strongest signal.
Bridge nodes — high betweenness centrality, presence across multiple Louvain communities — are the structural origin points of cross-community convergence. They're rarely the loudest in any single community; they're the ones whose work propagates without amplification.
Surface metrics (cross-platform presence, citation overlap) are necessary but not sufficient for true epistemic independence. Multiple sources may appear independent but all respond to the same upstream event, or share training data that correlates their outputs. Deeper provenance tracking and common-cause modeling are future work — acknowledged openly because the independence claim is the center of the methodology.
The dotted green line is the signal. Two contributors in different Louvain communities, each weighted by PageRank, both arriving at the same vector cluster.
06 \u2014 Recognition
How are leaders scored?
Four axes. None of them are followers.
The leader scoring system uses a four-axis contribution profile with explicit anti-virality bias. Follower count is excluded from every calculation. Engagement rate is excluded. The score is a function of what the contributor produces, where it lands, and whether other independent contributors converge on the same conclusions.
Originality
Normalized independence_contribution score: how often this contributor is the first in the citation graph to publish a vector that later appears in convergence patterns.
Independence
Inverse of community-cluster amplification. Contributors who consistently publish vectors that show up across multiple Louvain communities score high; contributors whose vectors only resonate within their own community score low.
Centrality
Pattern-involvement weight: total convergence patterns the contributor’s vectors participate in, weighted by pattern CI score. Not raw activity — only contributions that are part of detected convergence.
Source depth
Weighted score by content format: arXiv ≈ 1.0, GitHub ≈ 0.85, podcasts/long-form ≈ 0.6, blog posts ≈ 0.4, social media ≈ 0.15. Reflects the information density and verifiability of each source type.
Top live leader
0.428
07 \u2014 Preservation
What is frontier classification?
Classify, don't prune.
The protocol explicitly does not prune low-CI signals. Every detected pattern gets classified as Signal, Frontier, Noise, or Archived. Frontier patterns — low CI but unique frame, single or few contributors, high originality — are watch-list entries. They're the structural origin signals of future paradigm shifts. Pruning them is the mistake every recommender system makes.
Paradigm shifts are low-amplitude before they happen. The first person to articulate a contrarian thesis usually has minimal reach. By the time any conventional recommender notices the pattern is converging, the origin signal has been pruned by noise filters that reward early engagement. Frontier classification breaks this loop: low engagement is not noise.
Latest pipeline diff
2026-05-04
08 \u2014 Honesty
Where does the credibility come from?
Open methodology \u2014 and where it ends, today.
What's open
What's open: the ingest pipeline, the distillation prompts, the convergence detection algorithm, the leader scoring formulas, the prediction methodology, the token bake measurement, and every source URL behind every pattern. The system doesn't claim accuracy — it measures, publishes, and lets you audit.
Source selection is the only step that's not algorithmic. The protocol does not crawl the open web; it processes a human-curated source list. This is intentional: curation IS the value. But it's also the bottleneck — see below.
The limitation: a single curator
A single curator's source selection biases everything downstream — convergence detection only sees what the curator chose to track. The prediction scorecard reflects this, and methodology is currently in iteration. Single-curator credibility caps somewhere below 'open audit, validated predictive engine' until the curation layer itself can be verified.
Two mitigation paths under consideration
Today — single curator
Everything downstream inherits the curator's blind spots. The prediction scorecard reflects this — accuracy is bounded by source-selection bias, not just by convergence-detection quality.
Council — multiple curators
When 3+ independent curators include the same source or surface the same pattern, that's a meta-signal. Same convergence-detection logic Verg already uses for content, applied one layer up.
Path A \u2014 Council
More curators
Council curation: multiple curators each maintain their own source list. Convergence-across-curators (≥3 independent curators including the same source or surfacing the same pattern) becomes a meta-signal that's harder to fake than individual curation. Same convergence-detection logic Verg already runs on content, applied one layer up. Recruiting cost and governance are real, but the signal quality jump is dramatic.
Path B \u2014 Autoresearch
Find the curator's blind spots
Autoresearch algorithm: analyze the historical curator selections, identify clusters / gaps / biases, surface domains underrepresented relative to where convergence is happening elsewhere. Could grade the curator's own predictions to find systematic biases. Same score → attack → verify loop the convergence detection uses, applied to the curator's own choices.
Both mitigation paths are complementary. Council mode validates the curation layer through cross-curator convergence. Autoresearch surfaces the curator's blind spots from the inside. Long-term: both. Short-term: pick one to start. This page documents the limitation rather than papering over it because 'open methodology' is incompatible with hiding known weaknesses.
09 \u2014 Now
How can I try Verg?
Agents and humans. No auth required.
Verg is queryable today. Curl the API, install the MCP server, browse the live dashboard.
Reference
What does the whitepaper say?
The full reference text.
VERG: A Protocol for Convergence Intelligence
Draft v0.1 — April 2026
This document evolves with the system it describes.
1. Introduction
The internet produces more information than any human or institution can process. Trending algorithms surface what's popular. Social metrics surface what's amplified. Neither surfaces what's true.
The bottleneck is not access — it's intelligence. The ability to process raw data, verify independence, and derive insight. Most of what appears as consensus is actually echo: one person says something, others repeat it, and the amplification is mistaken for agreement.
Verg is a protocol for detecting genuine convergence — when independent minds arrive at the same conclusion without coordinating — and making that intelligence accessible to humans and AI agents.
2. The Convergence Thesis
When multiple independent actors begin converging on similar ideas, conceptual frames, or problem definitions without coordination, that convergence points at something real emerging in the structure of the present.
Three types of convergence carry different implications:
- Problem convergence: independent parties identify the same unsolved problem
- Metaphor convergence: the same mental model applied independently across domains
- Solution convergence: the same approach proposed by unconnected builders
The strength of convergence is measured not by volume (how many people say it) but by independence (how unconnected are the people saying it). Five independent researchers arriving at the same conclusion from different datasets is a stronger signal than five thousand people retweeting the same thread.
3. Protocol Design
3.1 Ingest
Multi-source, multi-format ingestion from the open internet:
- Academic papers (arXiv, Semantic Scholar)
- Open source repositories (GitHub trending, topic searches)
- Long-form content (YouTube talks, podcasts, RSS feeds)
- Snowball discovery: when the system identifies a new contributor, it automatically begins ingesting their public output
The source selection is curated — this is where human judgment enters the protocol. The pipeline is mechanical; the value is what you feed it.
3.2 Distill — The Token Bake
Every piece of curated intelligence has a processing cost. Verg tracks this as the token bake: the raw tokens of source content processed to produce each curated structured artifact.
A typical run, measured from the live data on disk:
~287,000 raw tokens of source content
↓
17 convergence patterns
~12,000 tokens of structured intelligence
~96% compression
The compression number is measured every run from JSON.stringify of the actual pattern artifacts (excluding foreign-key indices) divided by the actual body_text length of every contributing source. No estimates, no constants. Reproducible from data/research/token_efficiency.jsonl.
Each curated pattern is not a small summary — it's a structured intelligence object with four resolution tiers (prose summary, temporal/independence/frame analysis, modal distribution and conflict detection, and per-source profiles for every contributing creator). Agents ingest the full artifact; humans skim the summary tier.
The token bake serves three purposes:
1. Transparency: every claim links back to the raw sources that produced it
2. Efficiency metric: is the system getting better at extracting insight per token?
3. Value proposition: an agent querying Verg gets curated intelligence that would cost 100x to derive from scratch
3.3 Detect — Convergence Scoring
Each convergence pattern is scored on two axes:
- CI Score (Convergence Intelligence): strength of the convergence, based on how many independent vectors align and how closely their framing matches
- Independence Score: verified through social graph analysis — are the contributors genuinely independent, or are they echoing from the same community?
3.4 Classify — Signal, Frontier, Noise
The protocol does not prune low-scoring signals. It classifies them:
- Signal: high CI, high independence — genuine convergence, act on this
- Frontier: low CI, single source — a paradigm-shifting idea that hasn't converged yet. Could be noise. Could be early. Watch it.
- Noise: low CI, low independence — amplified echo, hot takes, clickbait
- Archived: was signal, isn't anymore — the convergence dissolved or was absorbed into consensus
Pruning destroys signal. Classifying preserves it. A source producing zero patterns today might be the origin of a paradigm shift in three months. The protocol watches for the moment other independent sources begin aligning with what one person said months ago.
3.5 Validate — Prediction Scorecard
The system generates predictions and grades itself:
- Weekly predictions: which vectors will cross consensus thresholds
- Monthly predictions: which concepts will enter mainstream discourse
- Running accuracy score: currently 80% on graded predictions
The scorecard is published. Anyone can verify the track record. If the system's predictions fail, the accuracy drops visibly. Trust is earned through transparent self-assessment, not claims.
4. Independence Verification
Independence is the hardest thing to verify and the most important.
The protocol uses social graph analysis to distinguish genuine convergence from coordinated echo:
- PageRank: who gets cited by important contributors (authority weight)
- Betweenness centrality: who bridges different communities (bridge score)
- Louvain community detection: which contributors belong to the same cluster
Two contributors in the same Louvain community who agree on something are potentially echoing each other. Two contributors in different communities who independently arrive at the same conclusion — that's signal.
5. Token Bake Economics
Every piece of human knowledge has a token cost — a measure of how much raw information was processed to produce it.
The token bake is both a metric and an economic primitive:
- Cost per insight: how many raw tokens does it take to produce one convergence pattern?
- Efficiency trending: is the system improving over time? (Better sources → fewer tokens wasted on noise)
- Source ROI: which feeds produce the most insight per token? (Academic papers may produce 1 pattern per 5K tokens. Low-quality RSS may produce 1 pattern per 50K tokens.)
The long-term direction: token bake as a publishable intelligence metric. "Verg processed X tokens to produce Y insights at Z% efficiency this month."
6. Contributor Recognition
Verg identifies thought leaders through contribution, not clout.
Scoring Dimensions
- Originality: does this person generate ideas that appear in convergence patterns independently?
- Independence: are they producing signal from their own work, or echoing others?
- Centrality: how central are they to the convergence patterns the system detects?
- Source depth: do they contribute through deep work (papers, repos) or shallow takes (tweets, hot takes)?
The Curated 30
The top 30 contributors are not "influencers." They are the people whose work consistently appears in high-independence convergence patterns. They earned the ranking through data, not through follower count.
Others can follow these contributors — not to amplify them, but to receive signal from people with a verified track record of genuine contribution.
7. Frontier Classification
The most valuable signal is often the loneliest.
A paradigm-shifting idea starts with one person. There's no convergence yet because nobody else has independently arrived at the same conclusion. By traditional metrics, this looks like noise — low engagement, no consensus, no trend.
The frontier classification watches for:
- Single-source ideas with high originality scores
- Ideas that don't match any existing convergence pattern
- Contributors with a track record of early signal generation
When other independent sources begin aligning with a frontier idea — when convergence starts forming around what was once a lone signal — the system flags the transition from frontier to emerging signal.
This is the moment of maximum value: the idea is real enough to have independent verification, but early enough to be ahead of consensus.
8. Self-Improving Properties
The protocol improves itself through three feedback loops:
Loop 1: Daily Pipeline (observe)
Ingest → distill → detect patterns → score sources → rank leaders.
Record what worked, what didn't, what's stale.
Loop 2: Weekly Research (learn)
Grade predictions against reality. Rank source quality. Track efficiency trends.
Identify which signal types are most accurate.
Loop 3: Auto-Tuning (adapt)
Calibrate confidence weights from accuracy data.
Shift ingest budget toward efficient content types.
Promote high-signal sources, demote noise generators.
Every adjustment is logged with its evidence and is reversible.
The system gets smarter by running. Not because a human tells it to change — because it measures its own performance and adjusts.
9. Agent Accessibility
Verg is designed to be queried by AI agents, not just browsed by humans.
- MCP Server: five tools (patterns, leaders, emerging, search, predict) that any AI agent can call as native tools
- llms.txt: standard discoverability file for AI crawlers
- Public API:
/api/patternswith rate limiting - Token bake in every response: agents know how much processing was saved
The long-term architecture: agents pay for curated intelligence via x402 micropayments. An agent querying Verg gets curated convergence patterns — structured intelligence artifacts that compress hundreds of thousands of raw source tokens into ~12K of distilled, audited, source-traceable content (typically a 95-97% reduction, measured per run). The protocol makes this exchange explicit and priced.
10. Open Methodology
The protocol's credibility comes from transparency:
- Source provenance: every pattern traces back through vectors to specific papers, repos, and talks with URLs
- Scoring methodology: CI score formula, independence weights, leader scoring dimensions — all inspectable
- Prediction scorecard: running accuracy, published, anyone can verify
- Self-grading: the system doesn't claim accuracy — it measures and publishes it
What is open: pipeline code, scoring algorithms, independence methodology, prediction track record.
What stays curated: source selection, domain intuition, the judgment of what to track. This is where human taste enters — like a DJ whose turntables are commodity but whose selection is the product.
11. Conclusion
Intelligence curation is becoming infrastructure. The question is not whether AI will process information at scale — it already does. The question is whether that processing will optimize for engagement (what's popular) or for truth (what's independently verified).
Verg bets on convergence as the closest thing to truth the internet can produce. Not consensus — convergence. Not popularity — independence. Not reach — contribution.
The thesis is either validated or honestly revised. The scorecard is public. The methodology is open. The track record speaks.
Verg — sourcing signal, removing noise, for builders.
@lazerhawk5000
Public Record
What audits have been published?
Public record of every signal/noise audit shipped by Verg. Each card links to the full detail page with the hypercard, probe measurements, and lifecycle events.
14 shipped
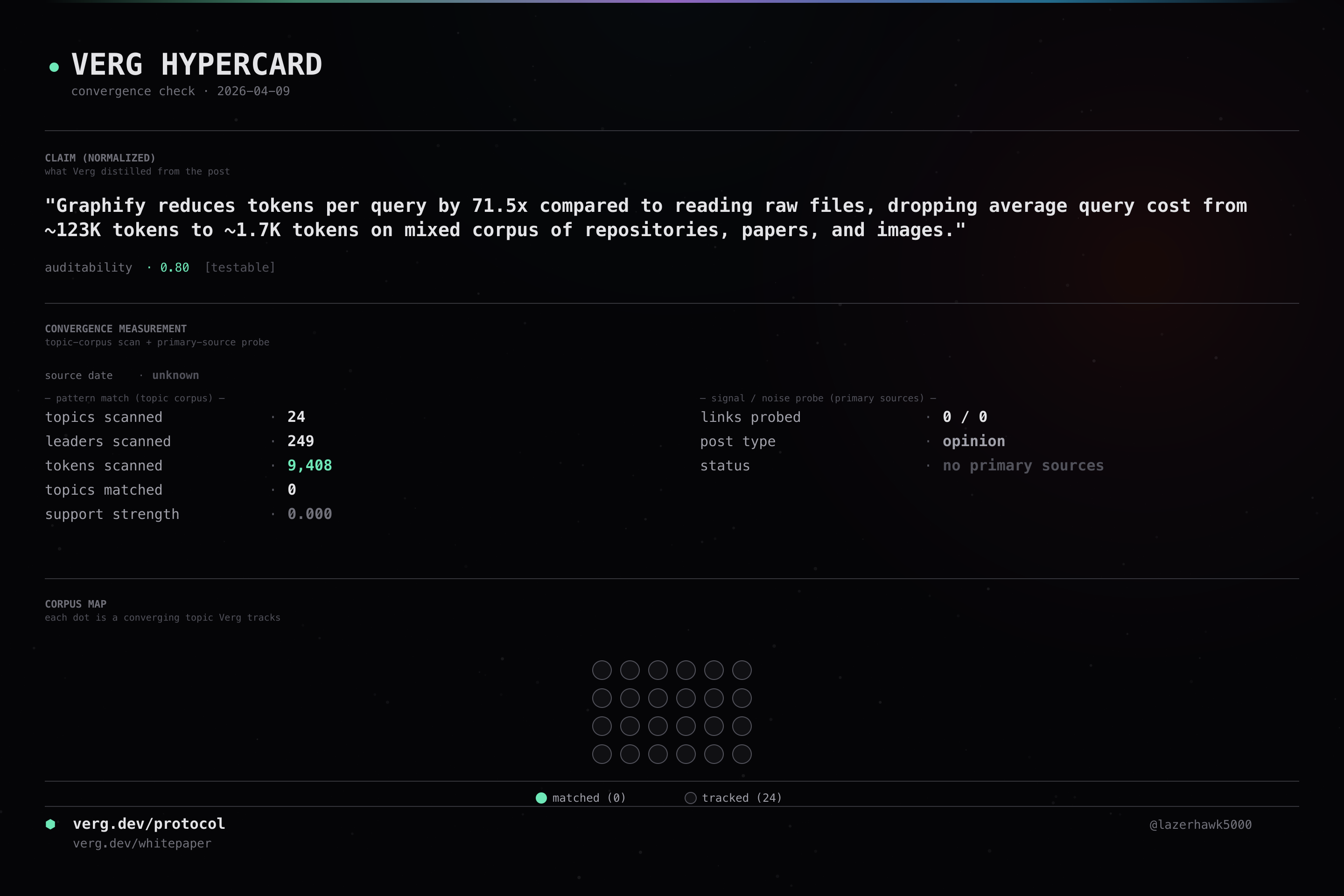
Graphify reduces tokens per query by 71.5x compared to reading raw files, dropping average query cost from ~123K tokens to ~1.7K tokens on mixed corpus of repositories, papers, and images.
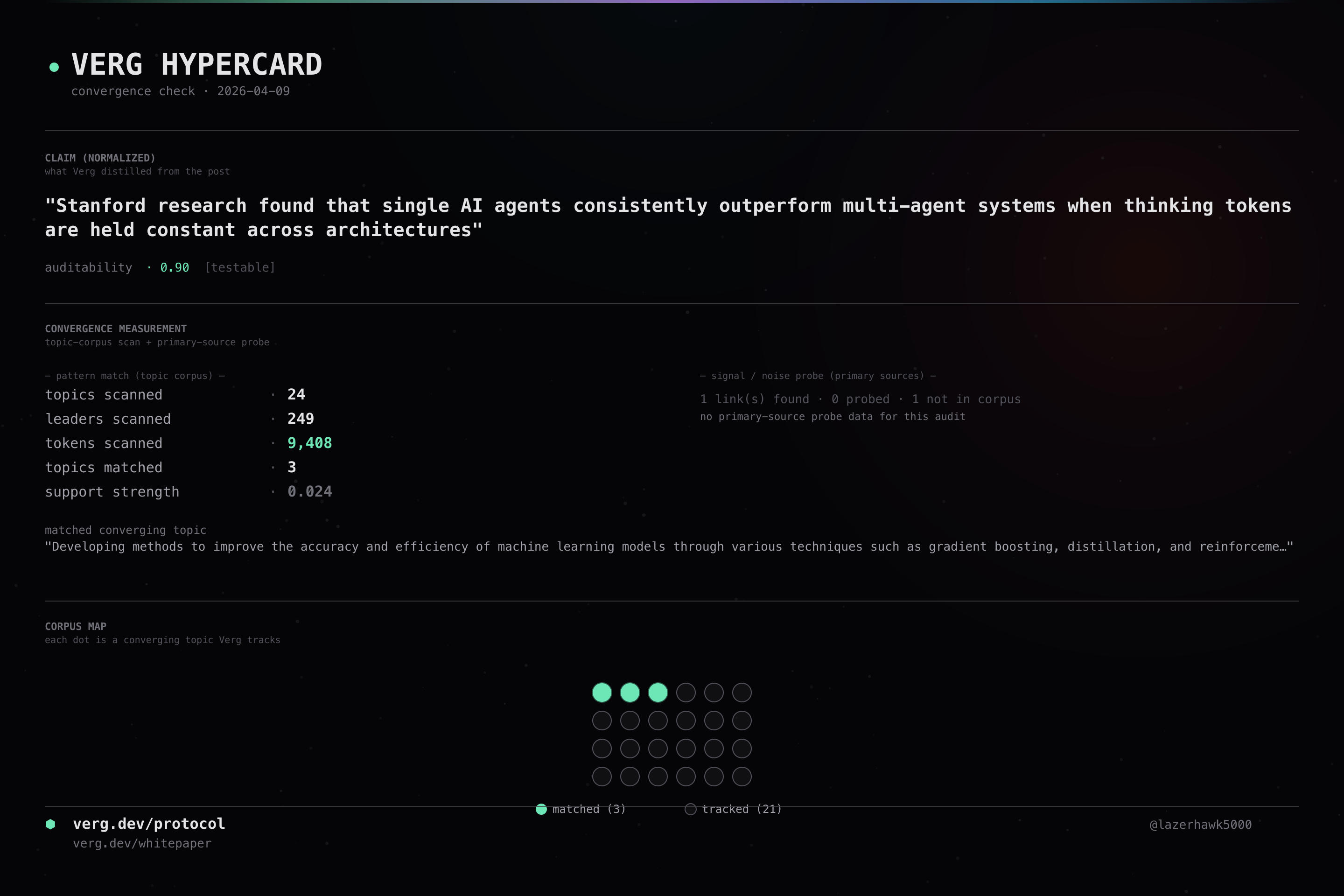
Stanford research found that single AI agents consistently outperform multi-agent systems when thinking tokens are held constant across architectures
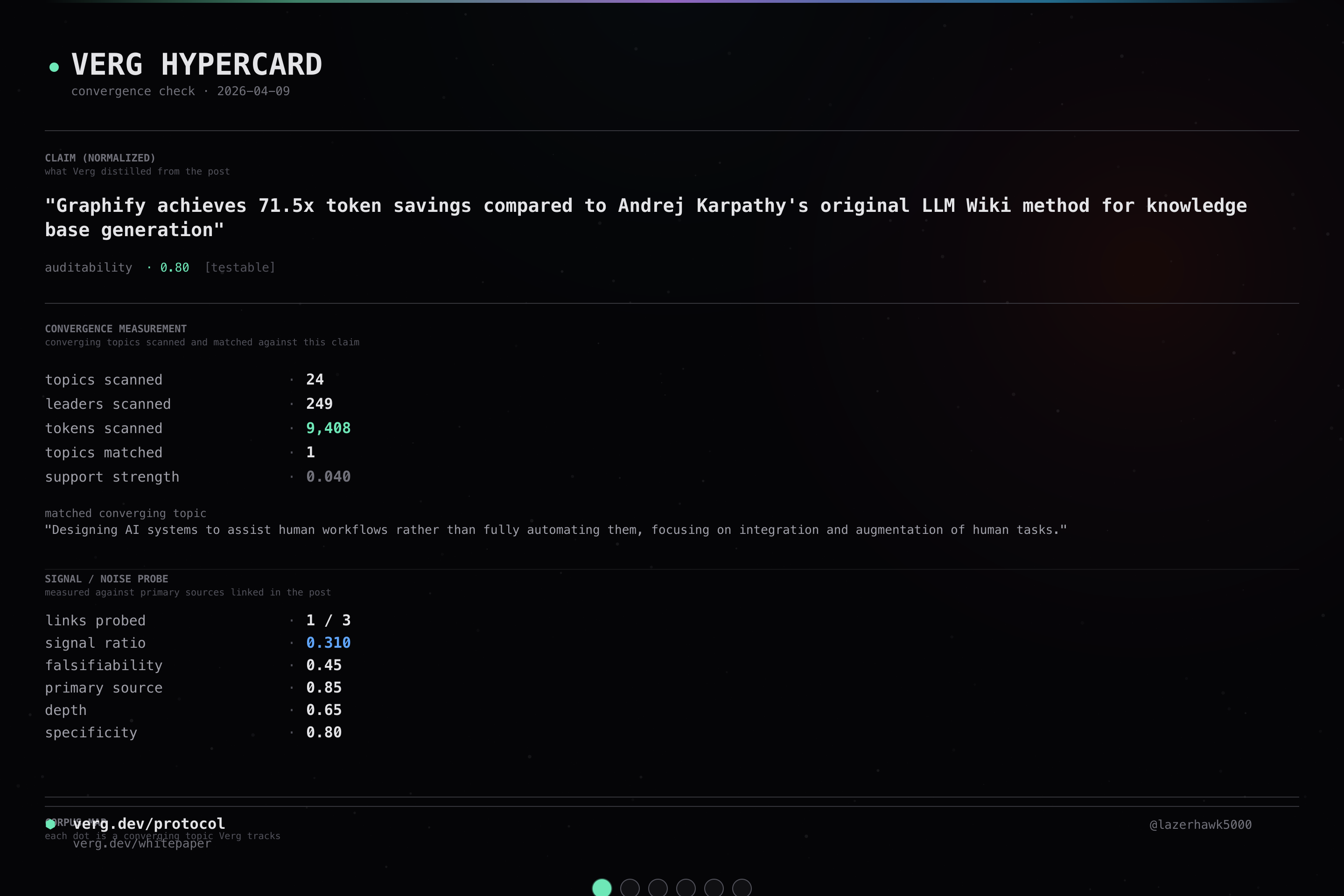
Graphify achieves 71.5x token savings compared to Andrej Karpathy's original LLM Wiki method for knowledge base generation
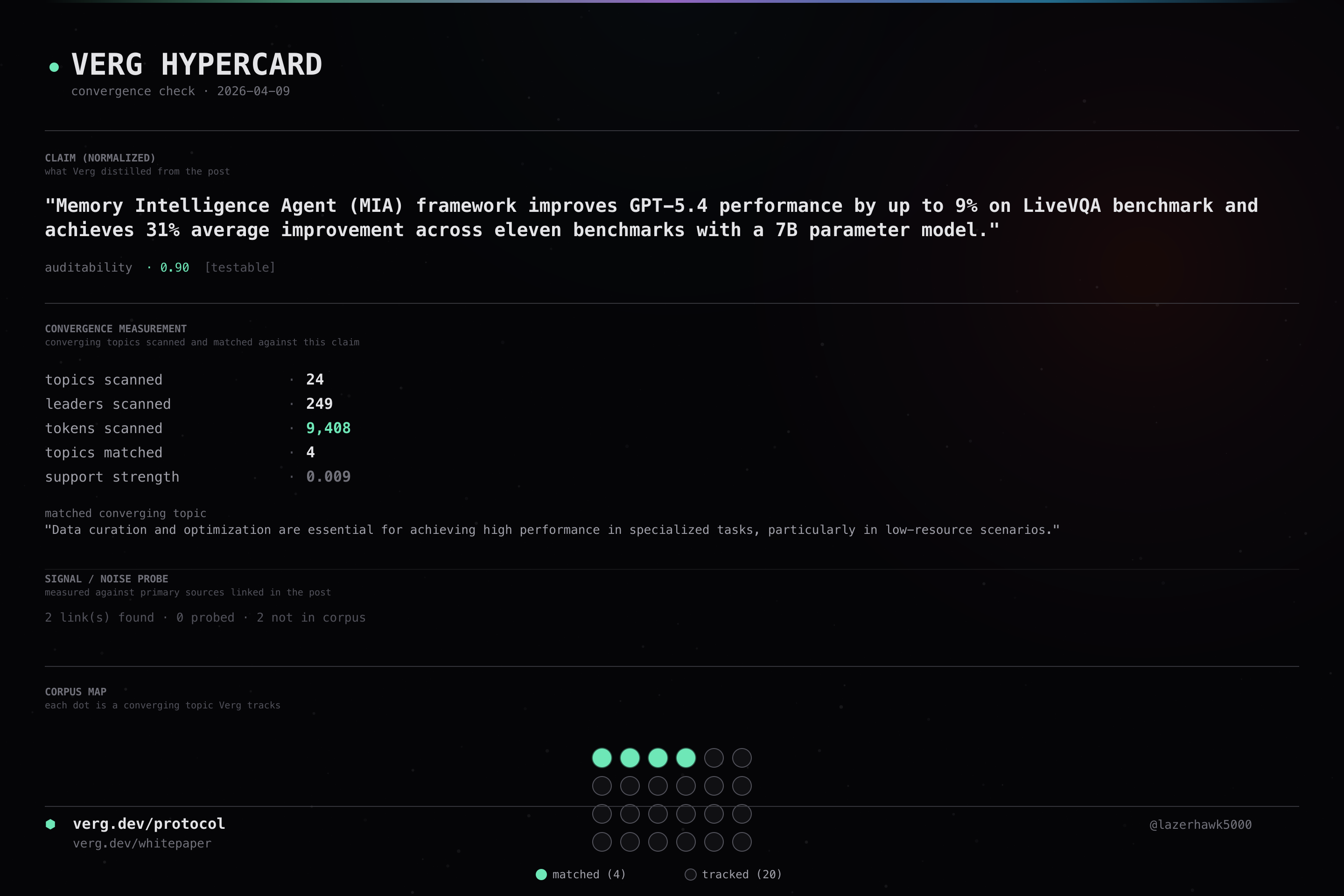
Memory Intelligence Agent (MIA) framework improves GPT-5.4 performance by up to 9% on LiveVQA benchmark and achieves 31% average improvement across eleven benchmarks with a 7B parameter model.
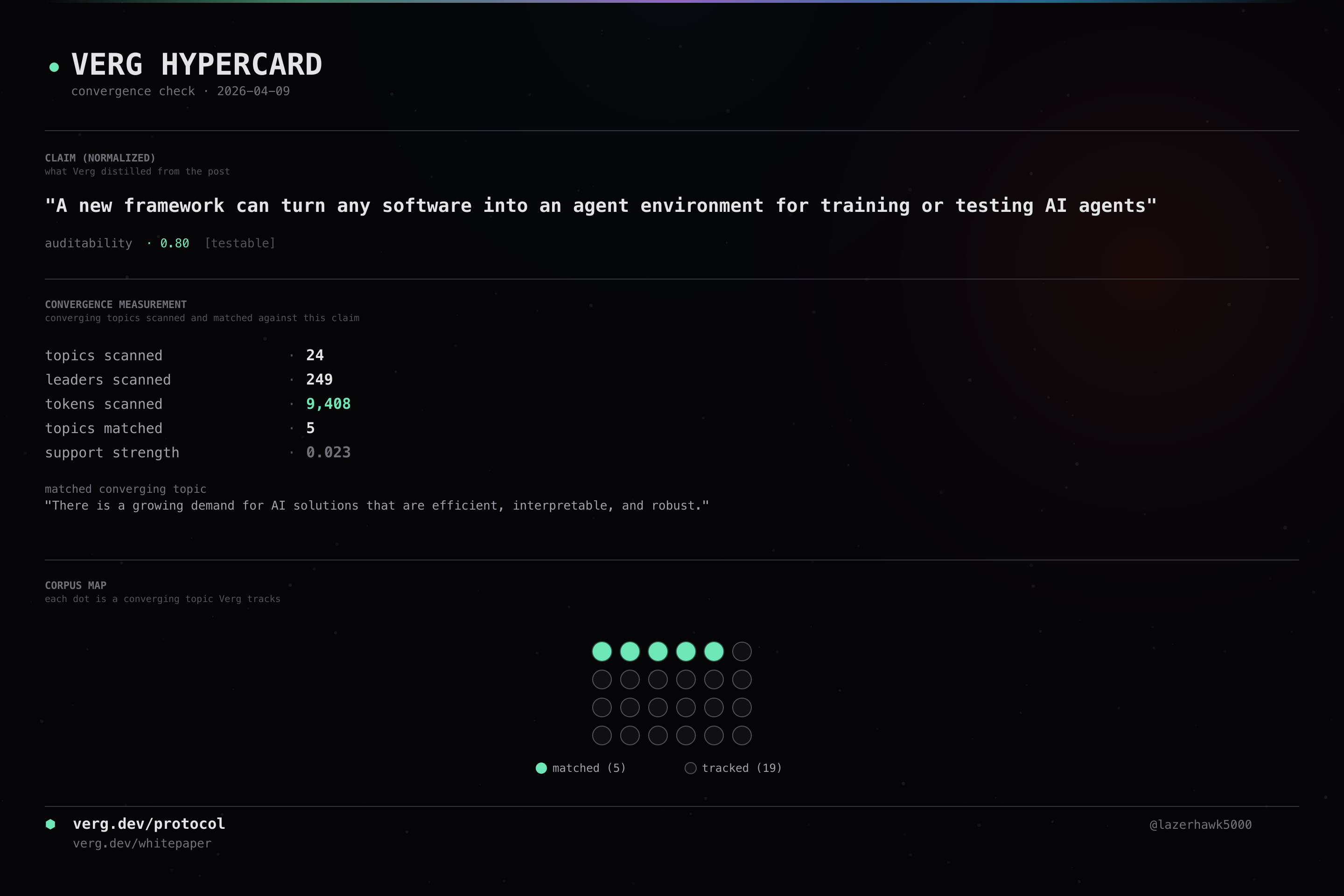
A new framework can turn any software into an agent environment for training or testing AI agents
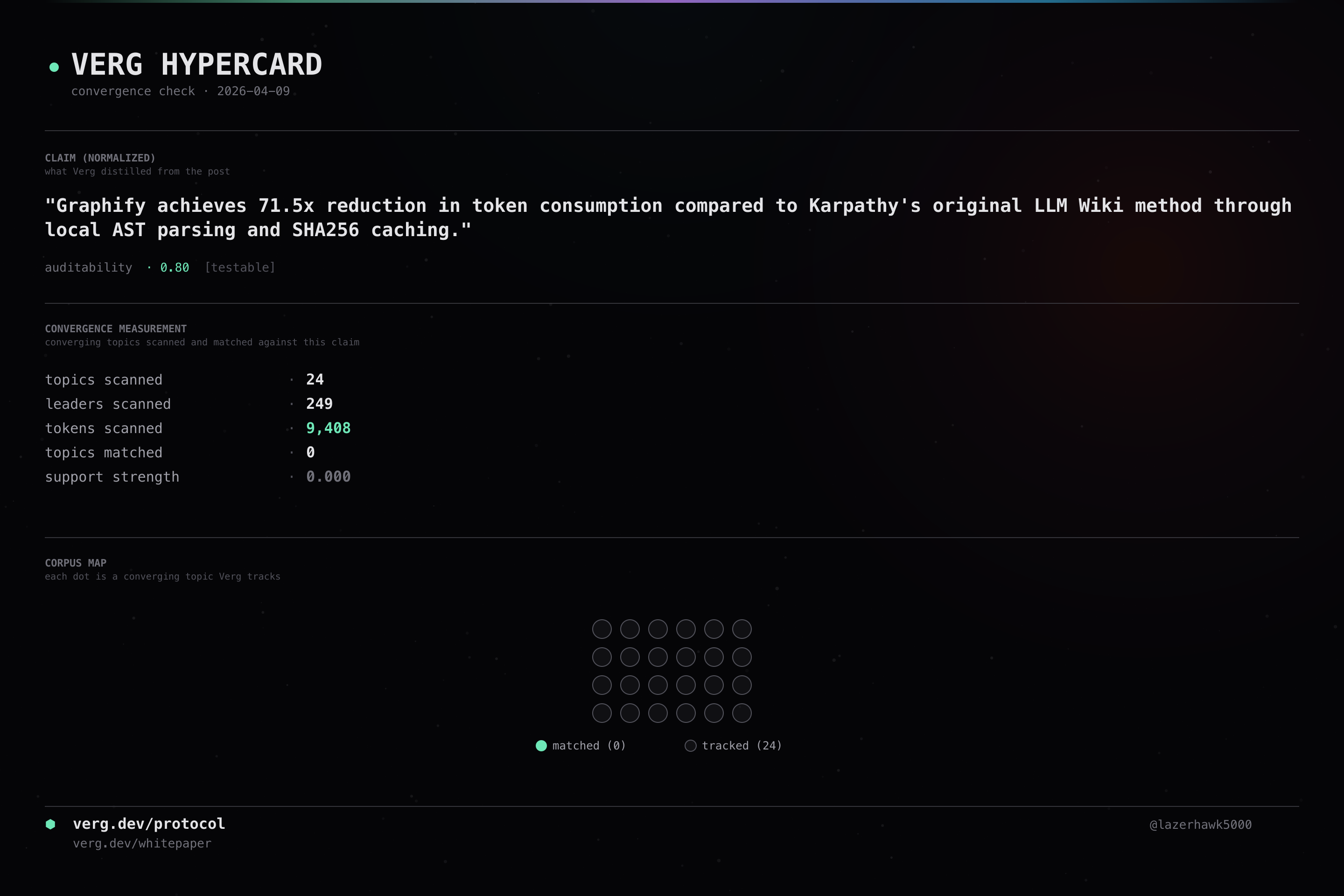
Graphify achieves 71.5x reduction in token consumption compared to Karpathy's original LLM Wiki method through local AST parsing and SHA256 caching.
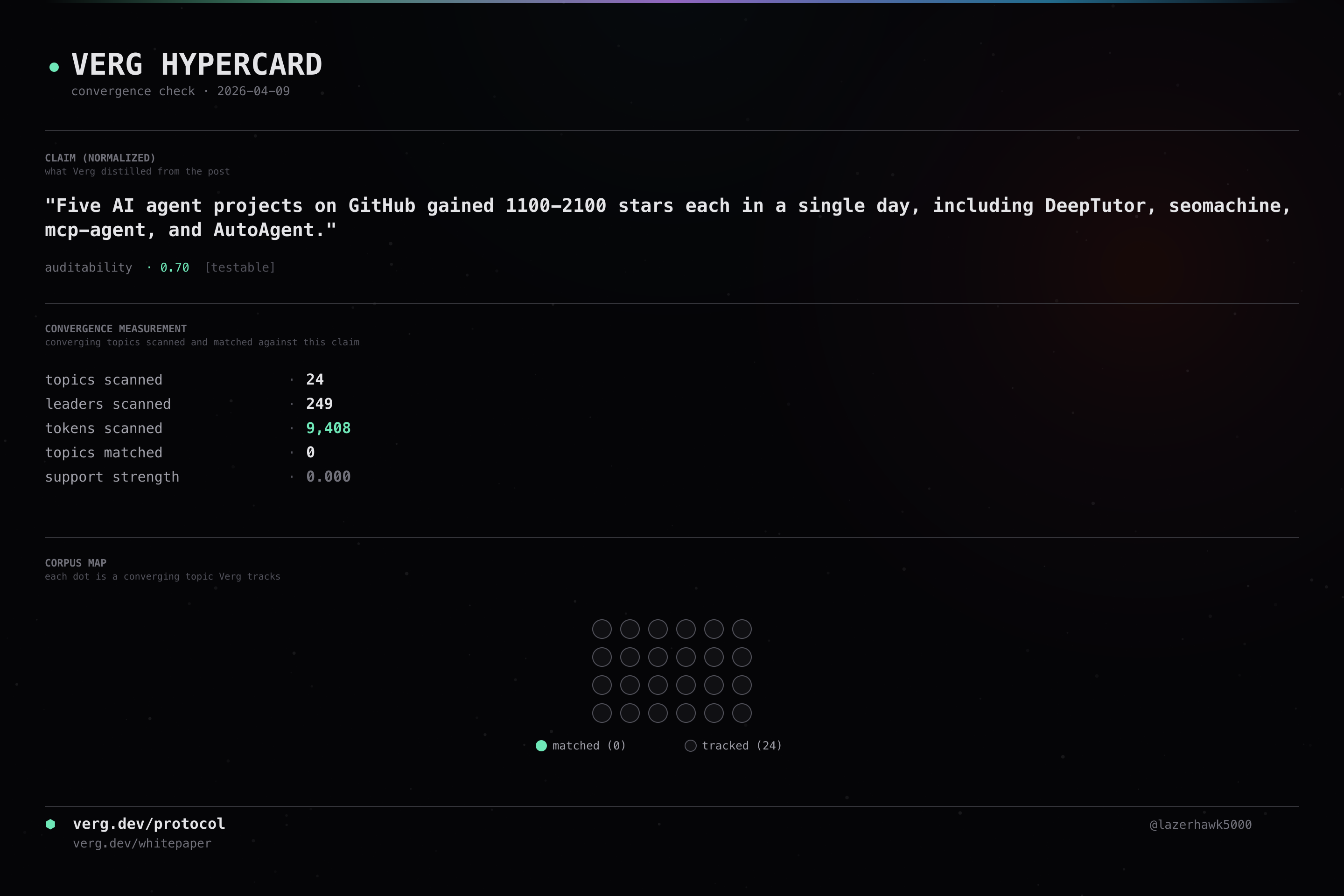
Five AI agent projects on GitHub gained 1100-2100 stars each in a single day, including DeepTutor, seomachine, mcp-agent, and AutoAgent.
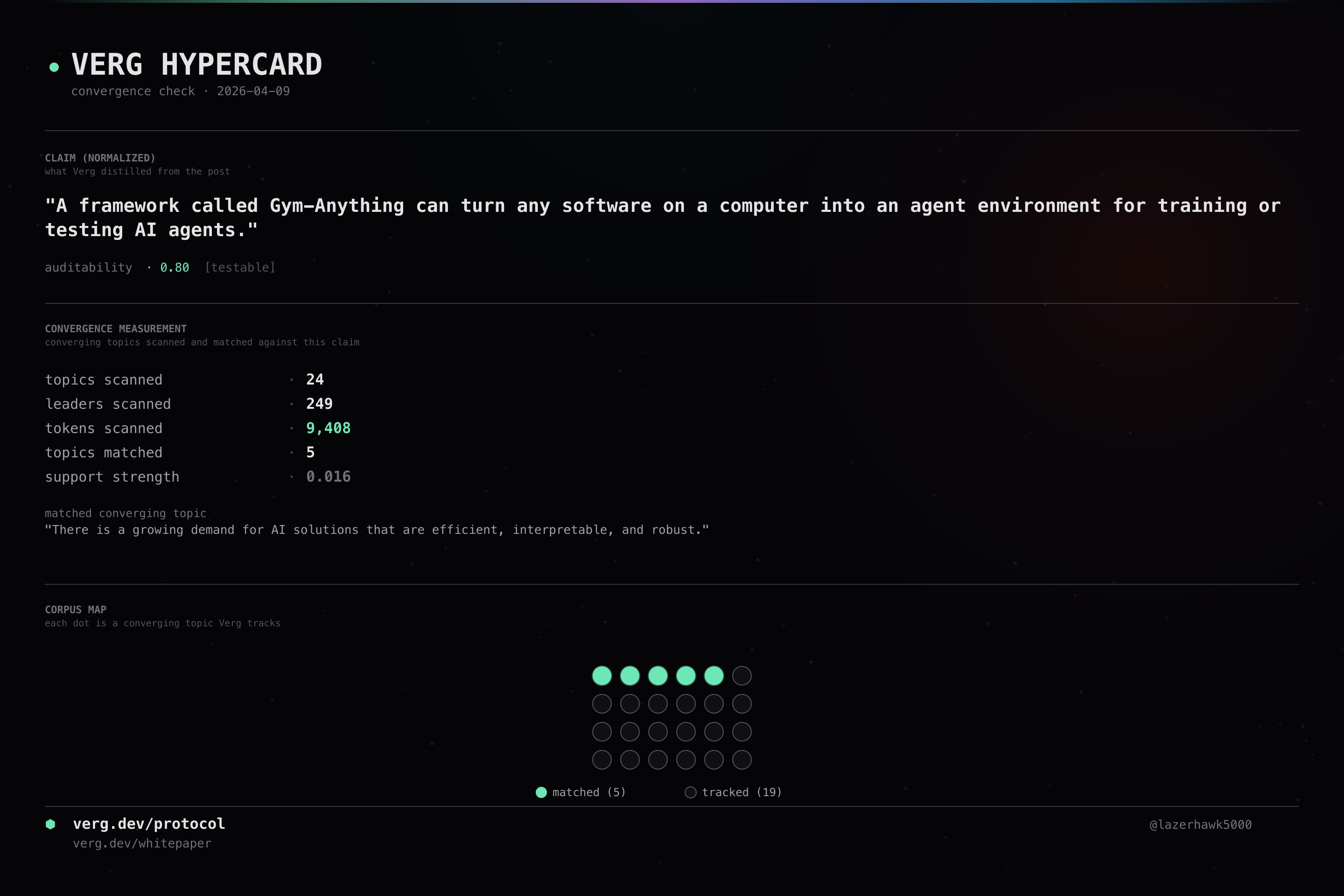
A framework called Gym-Anything can turn any software on a computer into an agent environment for training or testing AI agents.
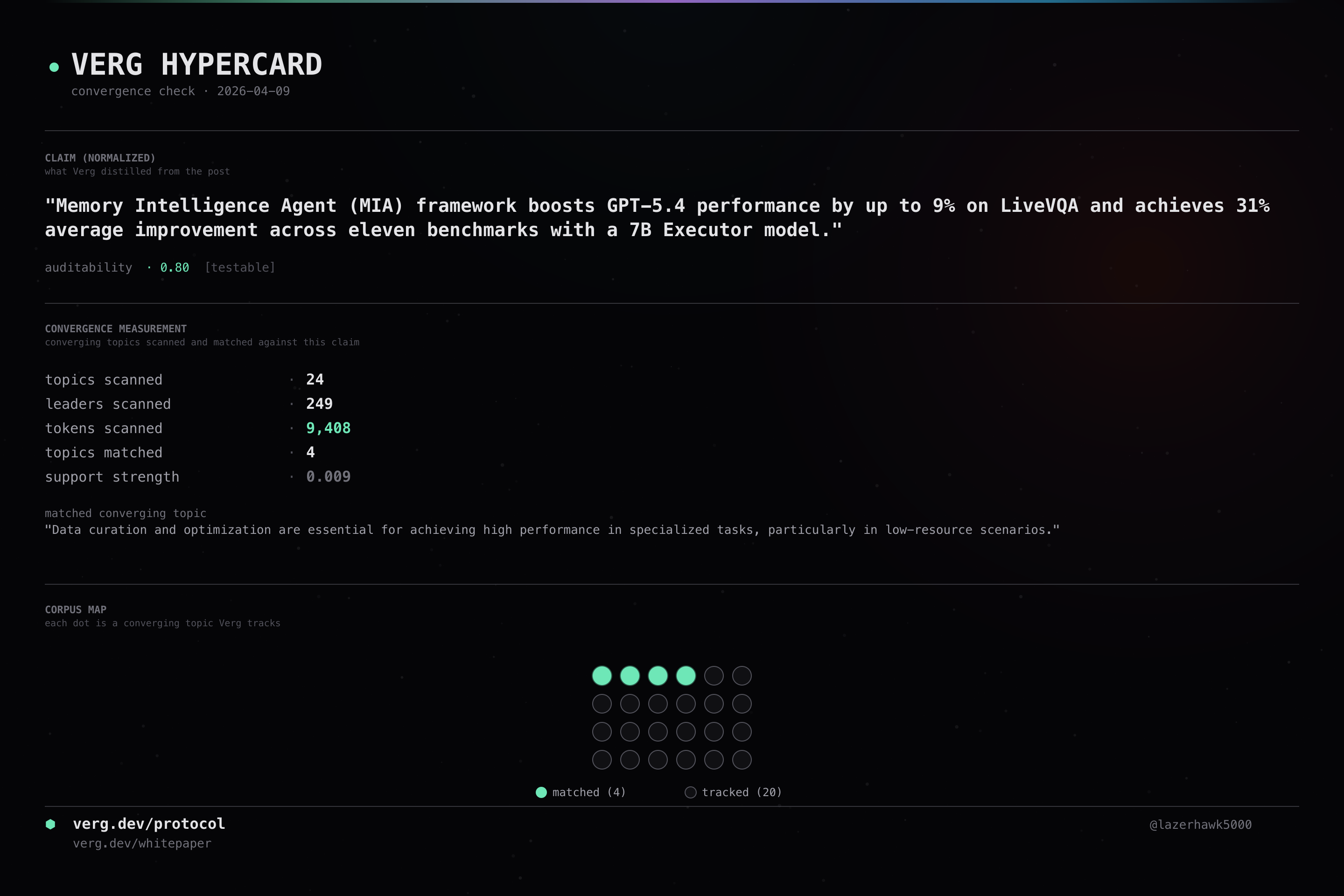
Memory Intelligence Agent (MIA) framework boosts GPT-5.4 performance by up to 9% on LiveVQA and achieves 31% average improvement across eleven benchmarks with a 7B Executor model.
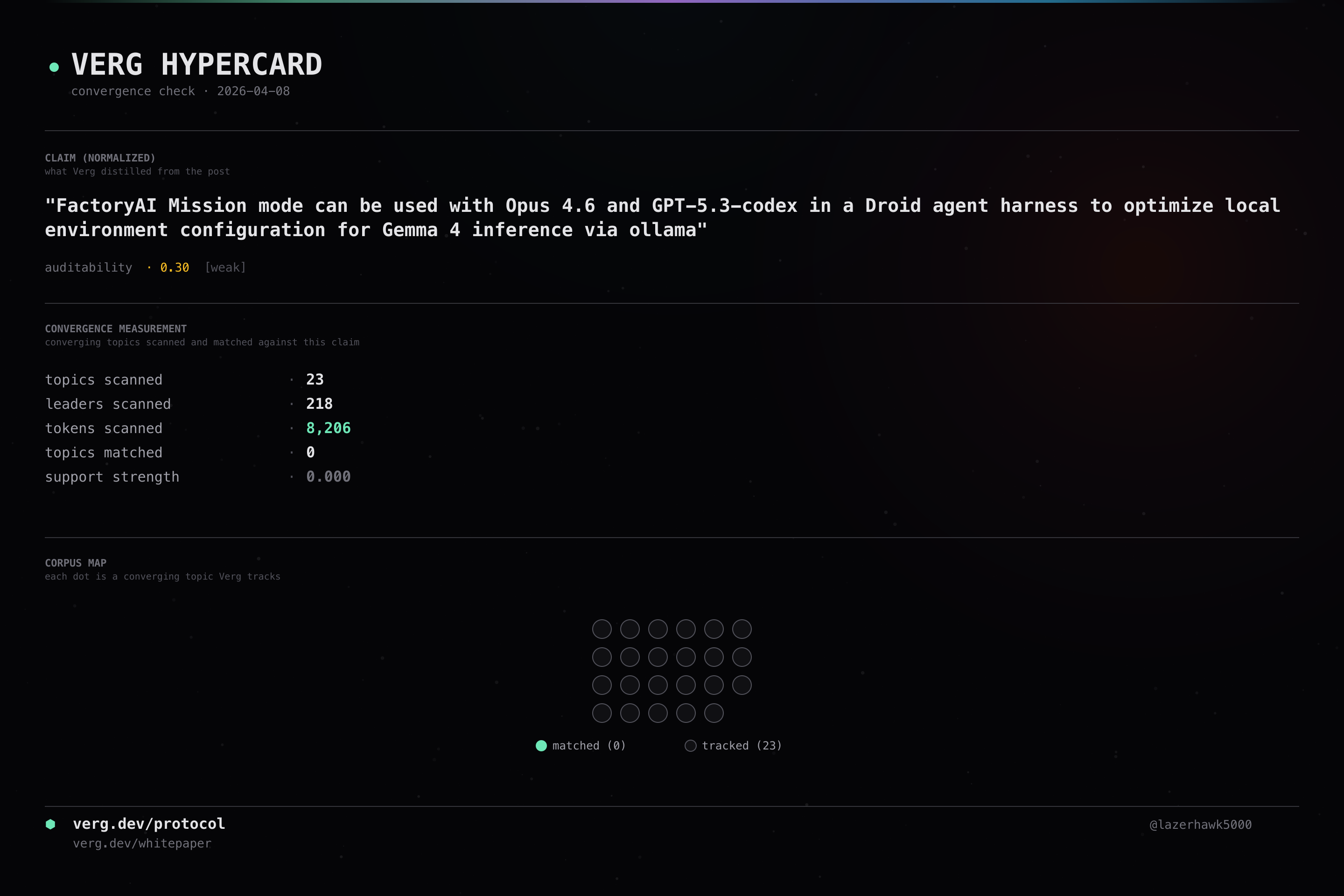
FactoryAI Mission mode can be used with Opus 4.6 and GPT-5.3-codex in a Droid agent harness to optimize local environment configuration for Gemma 4 inference via ollama
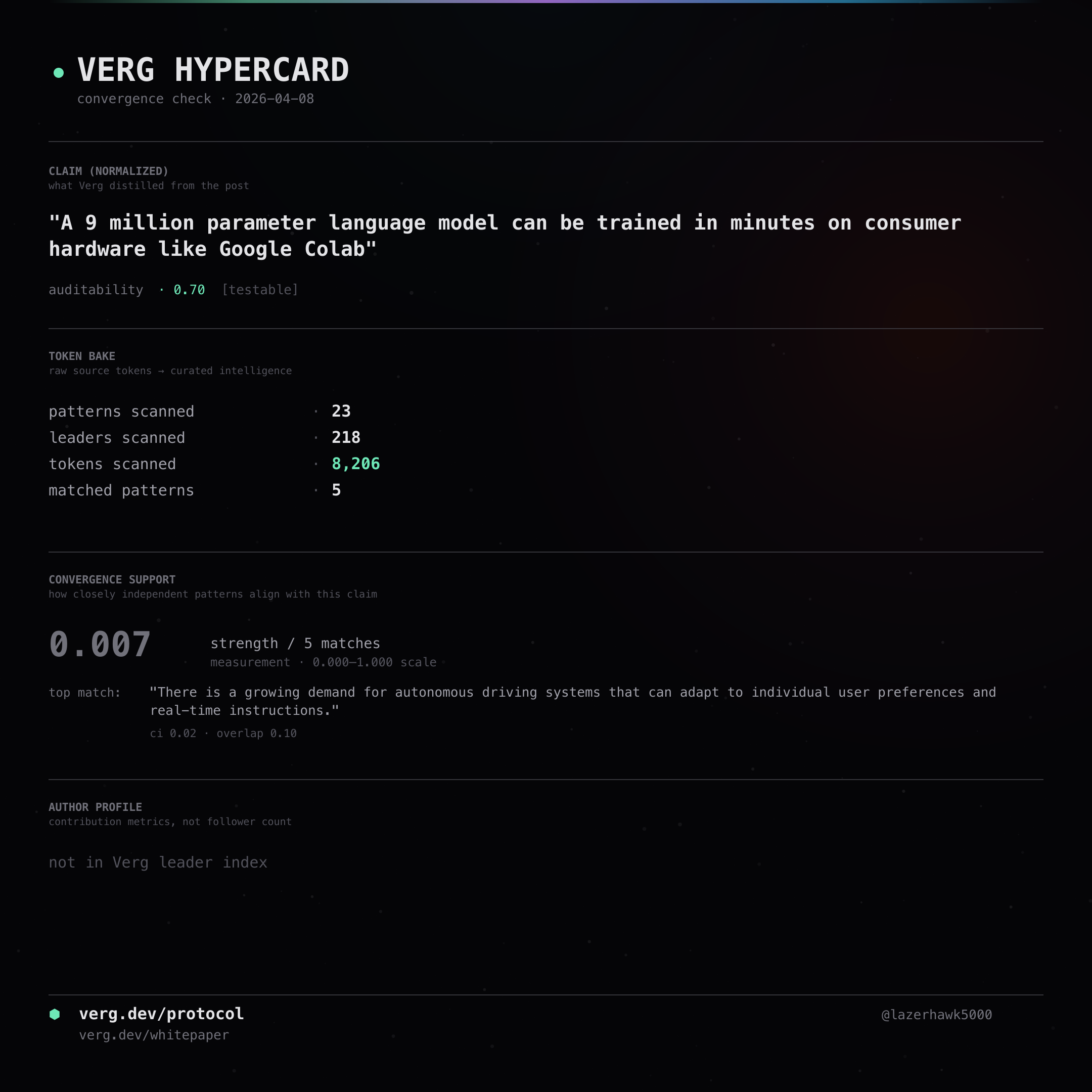
A 9 million parameter language model can be trained in minutes on consumer hardware like Google Colab
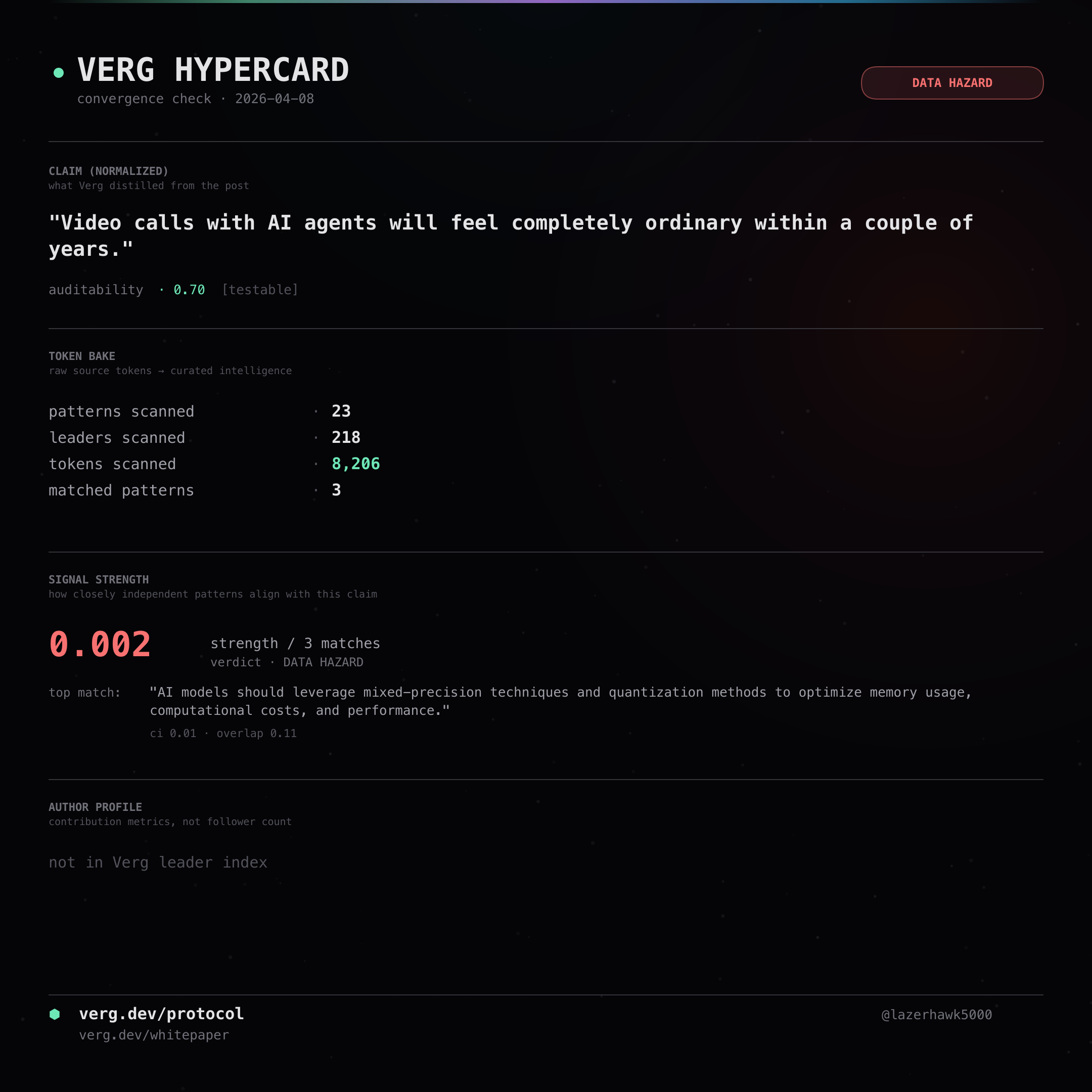
Video calls with AI agents will feel completely ordinary within a couple of years.
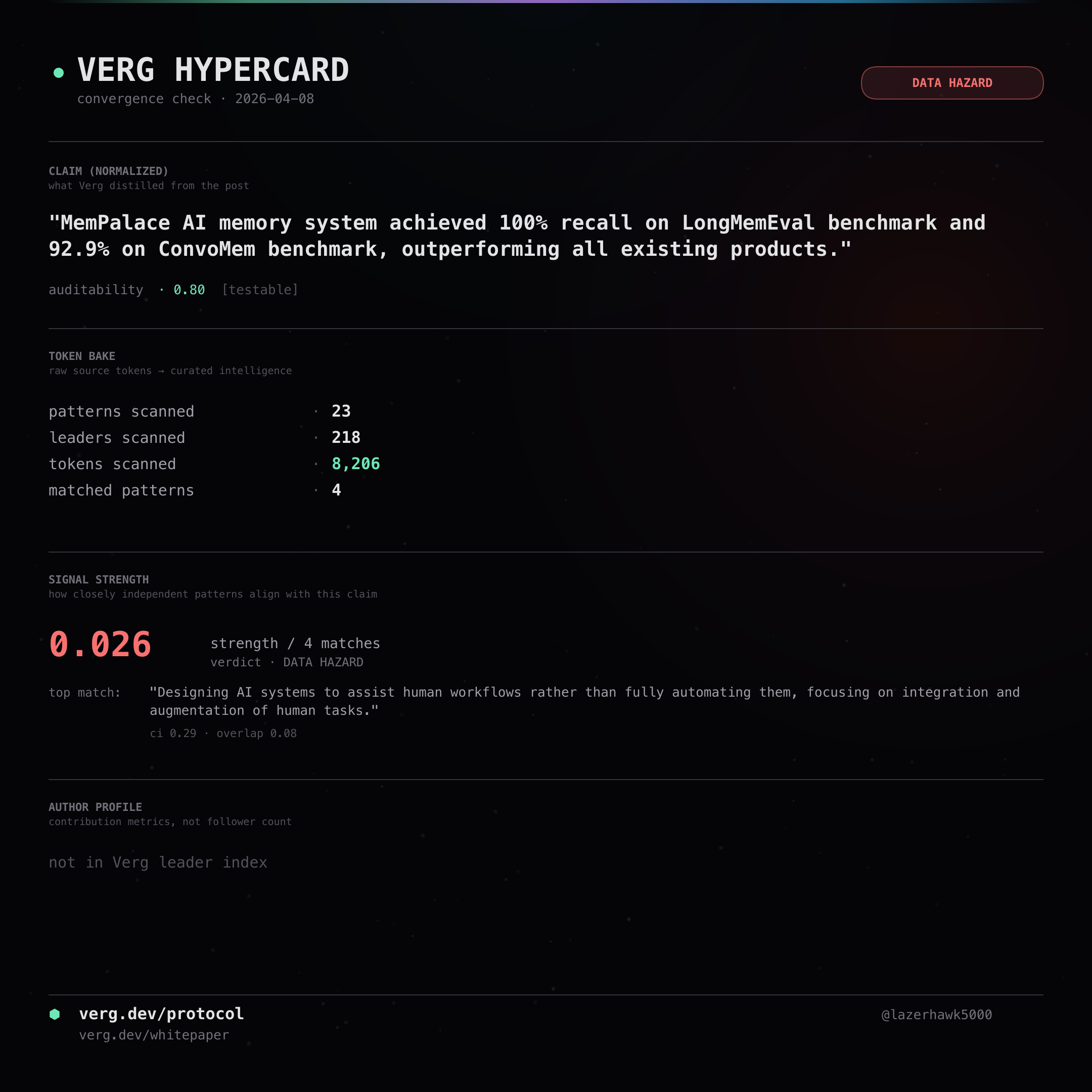
MemPalace AI memory system achieved 100% recall on LongMemEval benchmark and 92.9% on ConvoMem benchmark, outperforming all existing products.
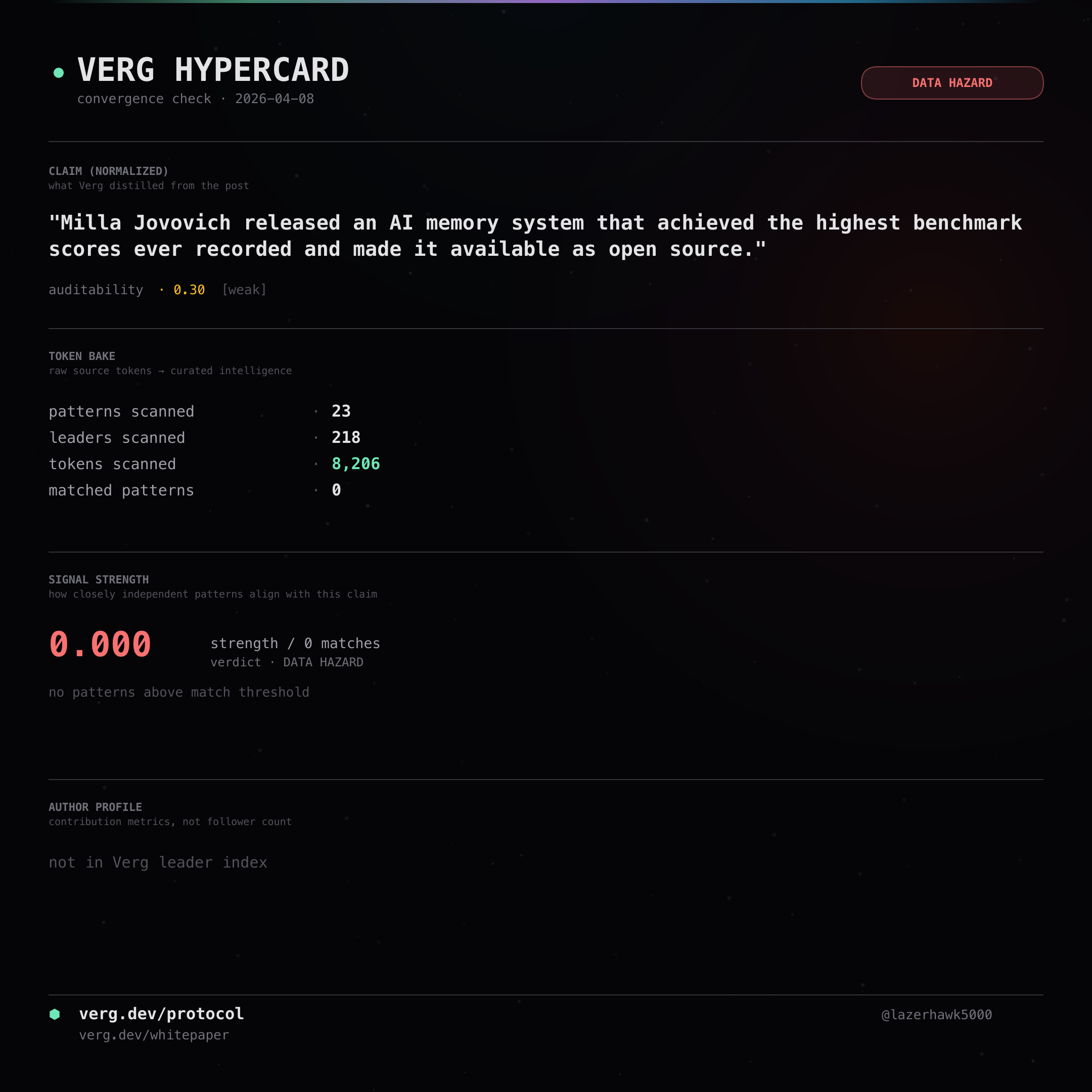
Milla Jovovich released an AI memory system that achieved the highest benchmark scores ever recorded and made it available as open source.
Falsifiability
How does Verg audit itself?
Verg measures itself against its own falsifiability gates.
Curation is Verg's biggest weakness. Every pattern is chosen by one person's taste. That's a single point of failure critics have rightly flagged. This section doesn't solve it. It surfaces it — honestly, with the same instruments we'd use on anyone else's claims.
Patterns analyzed
63
latest convergence.json
Mean novelty (counter)
n/a
Haiku skeptic verdict \u00b7 0=rehash \u00b7 1=novel
Contested
0
base curator & skeptic disagree
1 · Slurry test
Each pattern label is embedded (locally, via nomic-embed-text) and compared to a bank of 25 hand-written generic “AI trends right now” phrases. Cosine similarity ≥0.85 → the label is indistinguishable from what any LLM would produce given an empty prompt. Those patterns get flagged and de-ranked.
2 · Counter-curator
A second curation pass with a different taste. Where the base curator asks “what are sources converging on?”, the counter-curator (Claude Haiku) asks: “is this convergence genuinely novel, or a rebrand of something older?”
3 · Curator-space map
Every pattern plotted in base-curator × counter-curator space. X = CI score. Y = novelty rating. Click a point to see the pattern.
4 · Curator agreement
- aligned+ both curators agree this is signal
- aligned\u2212 both curators agree this is noise
- contested the curators disagree — worth a human look
- neutral neither strongly signal nor noise
7 · Outcome ledger
Every pipeline run snapshots each pattern's state. Over time this produces an empirical record — not a curator's opinion about what's signal, but what actually happened to each pattern.
tracked
1166
growing
0
stable
0
decaying
0
died
0
Survival rate: 0.0% · Growth rate: 0.0% · Spanning 18 days.
8 · What this tells us
- The current pattern set carries heavy substrate from prior decades. Mean novelty is — out of 1.0.
- The slurry test catches exactly what critics pointed to. The patterns called out as generic-sounding really are.
- Contested patterns are the ones worth a human's attention. When the two curators disagree, neither automated score is trustworthy on its own.
- This section updates automatically. Every pipeline run recomputes slurry, counter-curator, and agreement.